Note: All contents in this essay are from Self-supervised learning for Speech lectured by Hung-yi Lee, Abdelrahman Mohamed, Shinji Watanabe, Tara Sainath, Karen Livescu, Shang-Wen Li, Shu-wen Yang, Katrin Kirchhoff. Full video can be found here.
What is Self-Supervised Learning (SSL)?
There are various types of "learning" in Machine Learning. Among these "learning", supervised & representation learning are two famous learning methods.
Supervised Learning
Training with labeled data
Representation Learning
Unsupervised learning: Discover patterns in data without pre-assigned labels
Semi-supervised learning: use a small number of labeled samples to guide learning with a larger amount of unlabeled data
Self-supervised learning (SSL): uses information from input data as the label to learn representations useful for downstream tasks
SSL Framework
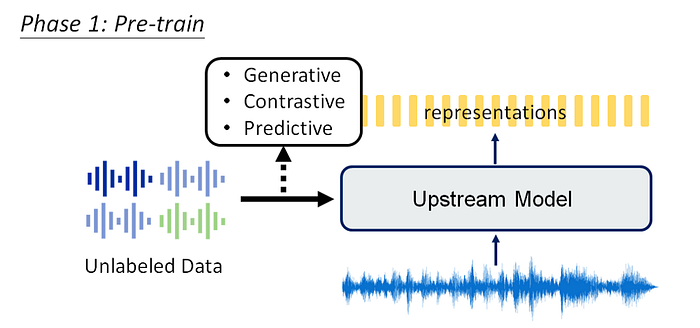
Phase 1: Pre-train
Use SSL to pre-train the model
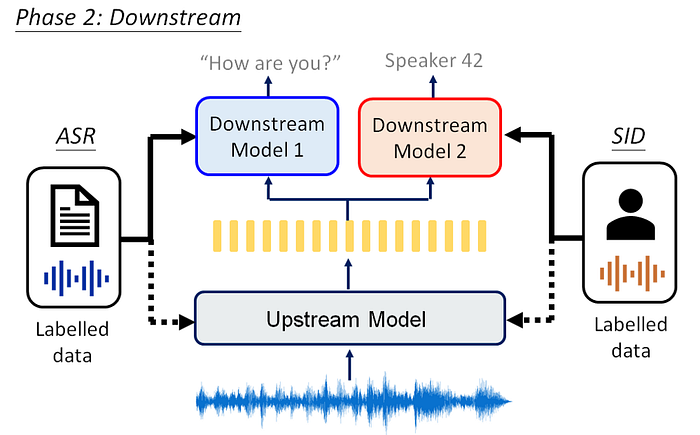
Phase 2: Apply to downstream tasks by the learned representation
What kinds of "Representation" is ideal ?
The representation should be able to satisfied the characteristic below:
Disentangled
There are many information in one utterance, including the content, emotion, speaker identity … . We want to be able to extract them separately into the representation.
Invariant
We want the representation to be robust regardless of background noise and channels.
Hierarchical
Learning feature hierarchies at the acoustic, lexical, and semantic levels which supports applications with different requirements.
Speech representation learning paradigms
What makes speech representation learning unique?
(1) Number of lexical units are different in different sequences.
(2) Not existing a clear boundary for a speech signal.
(3) Speech signal is continuous and lacks a predefined dictionary of units.
Speech representation learning methods
Contrastive approaches
(1) CPC
van den Oord et al, 2019 "Representation Learning with Contrastive Predictive Coding"
(2) Wav2vec 2.0
Baevski et al, 2020 "wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations"
Predictive approaches
(1) Hidden Unit BERT (Hubert)
Hsu et al 2021, "HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units"
(2) data2vec
Baevski et. al, 2022 "data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language"
Generative approaches
(1) Vector Quantised Variational AutoEncoder (VQ-VAE)
van den Oord et. al., 2017 "Neural Discrete Representation Learning"
(2) Autoregressive Predictive Coding (APC)
Chung et. al., 2019 "An Unsupervised Autoregressive Model for Speech Representation Learning"
(3) Masked Reconstruction Ling et. al., 2019 "Deep Contextualized Acoustic Representations For Semi-Supervised Speech Recognition"
Jiang et. al., 2019 "Improving Transformer-based Speech Recognition Using Unsupervised Pre-training"
Liu et. al., 2020 "TERA: Self-Supervised Learning of Transformer Encoder Representation for Speech"
Multi-modal SSL
Human speech is multi-modal !
Actually, during conversation, visual cues can't be ignored by listeners regardless of how hard they try.
Visual cues play an indispensable role in human conversation.
Types of multi-modal data
(1) Intrinsic: Multiple modalities associated with the speech itself
(2) Contextual: Additional modalities provide context beyond the speech signal
How to learn from multiple modal data ?
(1) Learning with intrinsic modalities

AV-HuBERT: An extension of HuBERT with multi-modal clusters
Learning with contextual modalities
Learning to relate images and spoken captions:
Given images and spoken captions, learn an image model and a speech model that produce similar representations for matched image/ caption pairs and dissimilar ones otherwise
Analysis of self-supervised representations
Now we know that SSL models and self-supervised representations are quite powerful. Therefore, we launch the following questions:
Can we gain deeper insights into how and why they work?
Do they generalize across languages?
Do they generalize to related (non-speech) tasks?
Information content at different layers
To test whether different layers do learn different information, we can apply following tests:
(1) evaluate the similarity of extracted embeddings from different layers with each other.
(2) Apply probing tasks to train downstream classifiers on representations from different layers.
(3) Analyze contributions of weights, hidden states to overall gradient of downstream objective function
Multilingual vs. Monolingual Pre-training
Multilingual training outperforms monolingual training even for small set of pre-training languages
From speech to sounds
No single representation is robust across all tasks.
As of yet, no self-supervised model for general-purpose audio processing
From Representation Learning to Zero Resources
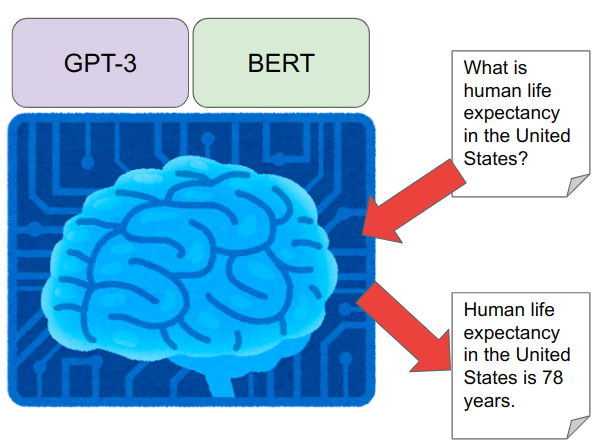
Pre-trained LM in NLP
Great success in various NLP tasks:
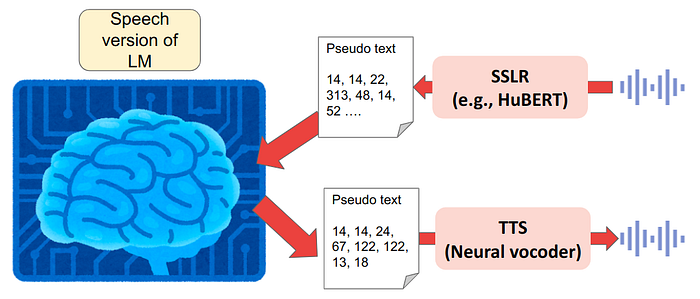
Generative Spoken Language Model (GSLM) Lakhotia+(2021)
Can we duplicate the same success with speech data ?
Topics beyond Accuracy
How to use SSL models ?
If we directly fine-tune SSL models on each downstream tasks, we will need to save plenty of gigantic models. Therefore, we want to apply one SSL models to all downstream tasks and only save a small proportion of weights.
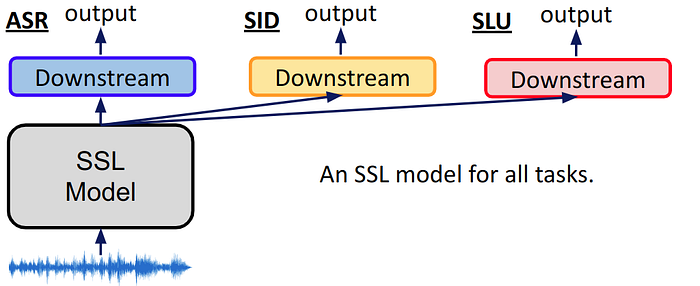
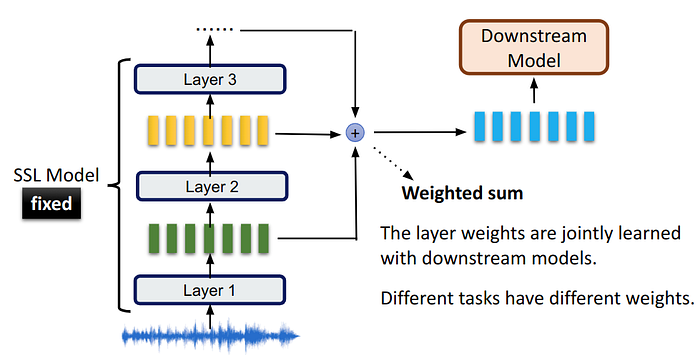
Solution 1: SSL models as feature extractor
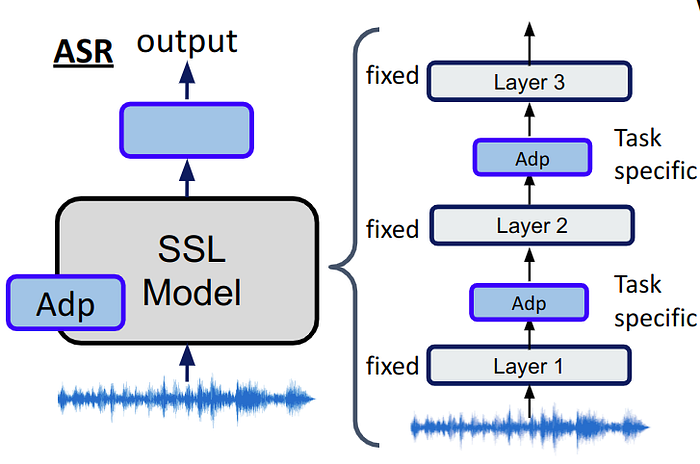
Solution 2: Apply adapter
Adapter is a widely used technique in NLP domain, which concatenates detachable layers in transformer model. During training, we only tune the adapter and freeze the transformer model.
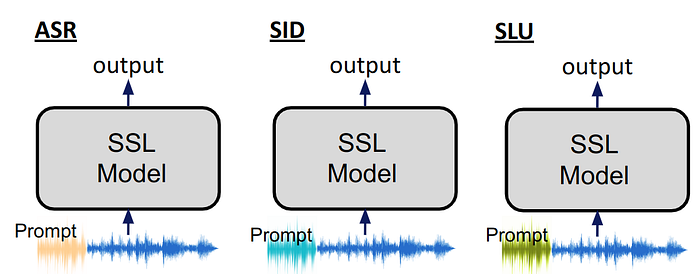
Solution 3: Apply Prompt
Prompt is another widely applied technique in NLP domain. The SSL model will solve different tasks by adding extra input "Prompt". During training, we only tune the prompt and freeze the transformer model.
Conclusion
SSL models are proven to be very powerful without labeled data. The self-supervised representation is also proven applicable to different downstream tasks. Also, we mention the concept of multi-modal data and how to learn from them. The tutorial also provides a comprehensive analysis of self-supervised representations, which is insightful and inspiring. Lastly, we talk about the zero resources training and topics beyond accuracy, which extends the SSL model to a broader horizon.