
Researchers at Tencent AI Lab have unveiled R-Zero, a groundbreaking framework that allows Large Language Models (LLMs) to evolve their reasoning abilities from zero data. By using a "Challenger" and "Solver" model in a co-evolutionary loop, R-Zero may unlock autonomous AI improvement.
For years, the path to more powerful Artificial Intelligence seemed straightforward: more data, bigger models, more compute. We've been feeding our Large Language Models (LLMs) a feast of human knowledge — the entirety of the internet, libraries of books, vast codebases. But a fundamental paradox looms over this approach. If an AI can only learn from what humans have already written, how can it ever fundamentally surpass human intelligence? We are, in effect, trapping our AIs within the confines of our own collective knowledge, asking them to discover new universes while only giving them a map of the old world.
This dependency on human-curated data is more than just a philosophical constraint; it's a practical bottleneck. It's expensive, labor-intensive, and slow. The dream of Artificial General Intelligence (AGI) isn't just about an AI that knows everything we know, but one that can reason, discover, and create things we cannot. To do that, AI must break free from its reliance on our data. It needs to be able to teach itself.
A stunning new paper from Tencent AI Lab, titled "R-Zero: Self-Evolving Reasoning LLM from Zero Data," presents a radical and electrifying new path forward. The researchers have developed a fully autonomous framework that allows an LLM to generate its own training data from scratch, creating a perpetual motion machine of self-improvement. It's a system that doesn't just learn; it learns how to learn, getting progressively smarter with zero pre-existing tasks or human-provided answers. This isn't just another incremental improvement; it's a paradigm shift in how we think about building intelligent systems.
Enter R-Zero: The AI That Teaches Itself
So, how do you teach a model without a textbook? The answer, inspired by the concept of self-play that created superhuman AI in games like Go and Chess, is to have the model play against itself. But instead of a game board, the arena is the boundless space of mathematical and logical reasoning.
The R-Zero framework, at its heart, is beautifully elegant. It takes a single base LLM and initializes two distinct versions of it with different roles: a Challenger and a Solver.
Imagine a timeless duel between a grandmaster and their prodigious apprentice.
- The Challenger acts as the grandmaster. Its sole purpose is to invent novel, challenging problems — puzzles that are precisely at the edge of the apprentice's current abilities.
- The Solver is the apprentice. Its job is to marshal all its reasoning power to crack the puzzles set by its master.
These two models are locked in a co-evolutionary dance. The Challenger generates a tough question. The Solver tries its best to answer it. If the Solver succeeds, it gets stronger. This new, stronger Solver now presents a higher bar of competence. In response, the Challenger is forced to dig deeper, to invent an even more difficult and nuanced problem to continue pushing the Solver. This virtuous cycle repeats, with both models spiraling upwards in capability, creating their own ever-escalating curriculum.
This dynamic process produces a targeted, self-improving curriculum without requiring any pre-existing tasks or labels. The entire system bootstraps its own intelligence, starting from nothing but the base model's initial capabilities.
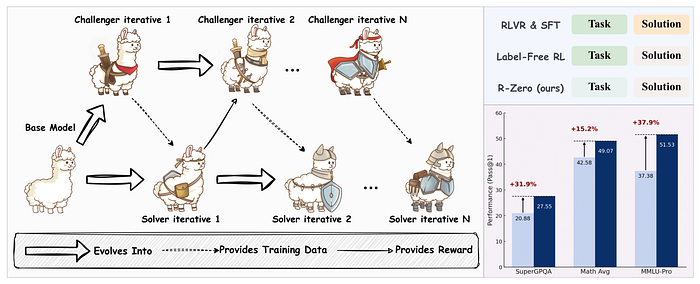
The Engine of Self-Improvement: How R-Zero Creates Its Own Curriculum
The conceptual elegance of a Challenger and Solver is one thing, but making it work requires solving two incredibly difficult technical problems:
- How does the Challenger know if a question is "challenging" without knowing the answer itself?
- How does the Solver learn to be correct without a human-provided answer key?
The solutions devised by the R-Zero authors are the core technical genius of this work.
The "Uncertainty Reward": Finding the Edge of Knowledge
To create perfectly tailored problems, the Challenger doesn't need to know if an answer is right or wrong. It only needs to know how confident the Solver is.
Here's how it works: For any new question the Challenger proposes, the current (frozen) Solver is asked to answer it multiple times (say, 10 times). The Challenger then looks at the consistency of the answers.
- If the Solver gives the exact same answer all 10 times, the question was likely too easy. The Challenger receives a low reward.
- If the Solver gives 10 completely different, random-looking answers, the question was probably too hard or nonsensical. Again, a low reward.
- The sweet spot — the maximum reward for the Challenger — is when the Solver's answers are maximally uncertain. This happens when its success rate is around 50% (e.g., it produces one answer 5 times and another answer 5 times).
This 50% success rate is the frontier of the Solver's ability — the zone of proximal development where learning is most efficient. The paper provides a theoretical analysis showing this point of maximum variance corresponds to the greatest potential for learning. By rewarding the Challenger for inducing this 50/50 split, the framework automatically guides the curriculum to be perfectly, adaptively difficult.
Majority Vote as Ground Truth: Learning from Self-Consistency
The Solver's side of the puzzle is just as clever. Without a human teacher, how does it know which of its answers to learn from? It uses a democratic process: majority vote.
For a challenging question posed by the Challenger, the Solver again generates a batch of answers. The most frequent response among them is designated as the "pseudo-label" — the temporary ground truth. The Solver is then fine-tuned to become better at producing this majority-voted answer.
Crucially, this is not a blind process. The framework includes a filtering step. It only uses questions for training where the consistency falls within an "informative band" (e.g., between 30% and 70% of answers agree). This brilliantly serves a dual purpose:
- Curriculum Pacing: It discards tasks that are too easy (100% consensus) or too hard (no clear majority), focusing the Solver's efforts where they matter most.
- Implicit Quality Control: Questions that result in very low consistency are often ambiguous, ill-posed, or simply flawed. By filtering them out, the system automatically purges low-quality, self-generated data, improving the reliability of the pseudo-labels it learns from.
Technical Deep Dive: Inside the Co-Evolutionary Loop of Challenger and Solver
For those who want to look under the hood, the entire R-Zero framework is orchestrated using an advanced reinforcement learning (RL) algorithm called Group Relative Policy Optimization (GRPO).
GRPO is a memory-efficient RL algorithm that is particularly well-suited for training large models. Unlike older methods such as Proximal Policy Optimization (PPO), GRPO does not require a separate "critic" or "value function" model to estimate rewards, which significantly reduces memory usage. Instead, it generates a group of responses for a given prompt, calculates the reward for each, and then uses the mean reward of the group as a baseline. An answer is considered good (and receives a positive advantage) if its reward is higher than the group's average. This critic-free, relative evaluation makes the training process more stable and efficient.
The R-Zero loop can be summarized in these steps:
1. Challenger Training: The Challenger's policy is trained using GRPO. It generates a batch of questions. For each question, the frozen Solver generates multiple answers to calculate the r_uncertainty reward. An additional r_rep_penalty is used to discourage the Challenger from generating duplicate questions. The final reward guides the Challenger to produce diverse questions at the edge of the Solver's ability.
r_i = max(0, r_uncertainty(x_i; S_phi) - r_rep(x_i))
2. Solver Dataset Construction: A large pool of candidate questions is generated by the newly updated Challenger. For each question, the Solver generates m answers. Questions are filtered and kept only if the majority vote consistency is within a specific range (e.g., |p_i - 0.5| < delta), creating a high-signal training set S.
3. Solver Training: The Solver's policy is then fine-tuned on the dataset S, also using GRPO. Here, the reward is much simpler. For a given question x_i and its majority-voted pseudo-label y_i, the Solver gets a binary reward: 1 if its generated answer matches the pseudo-label, 0 otherwise. This hones the Solver's ability to correctly answer the difficult questions its counterpart has created.
4. Iteration: The roles are swapped. The newly trained Solver becomes the frozen model against which a new Challenger is trained. The entire process repeats, forming a self-contained, self-evolving cycle that operates without any human intervention.
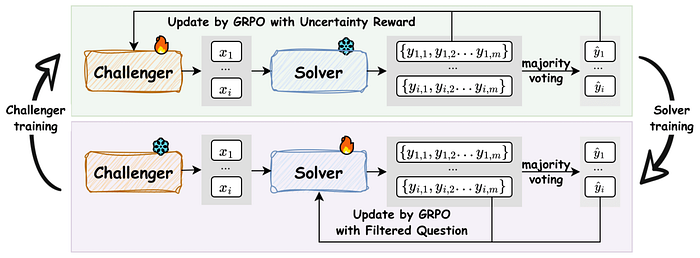
From Zero to Hero: R-Zero's Remarkable Performance Gains
The most critical question is, does it actually work? The empirical results presented in the paper are nothing short of remarkable. The authors tested R-Zero on a variety of backbone LLMs (including the Qwen and OctoThinker families) and evaluated them on tough mathematical and general-domain reasoning benchmarks.
Stunning Gains in Mathematical Reasoning: The iterative training process consistently and substantially improves the base models' performance. For instance, after three iterations of R-Zero, the Qwen3–8B-Base model's average math benchmark score jumped from 49.18 to 54.69 — a massive +5.51 point gain. Even more impressively, the smaller Qwen3–4B-Base model saw its score on math benchmarks boosted by +6.49 points. The performance gains are progressive, demonstrating the power of the co-evolutionary curriculum.
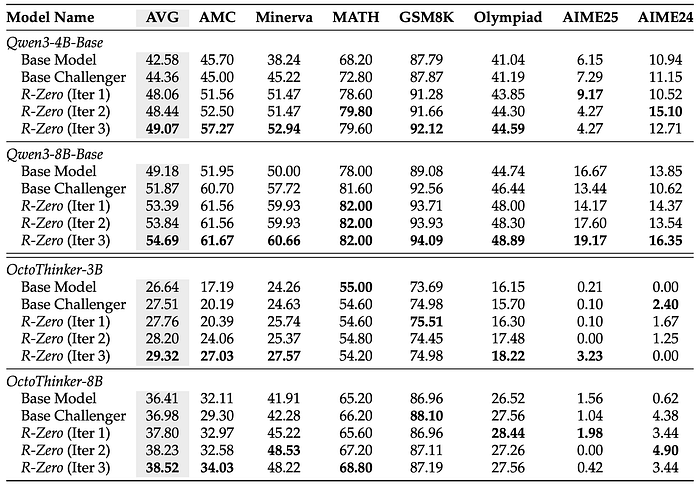
Generalization to Broader Reasoning: Perhaps the most exciting finding is that these skills, honed on math problems, transfer to general reasoning tasks. This confirms that R-Zero isn't just teaching domain-specific tricks; it's enhancing the model's core underlying reasoning capabilities. After three iterations, the general-domain reasoning score of Qwen3–8B-Base improved by +3.81 points.
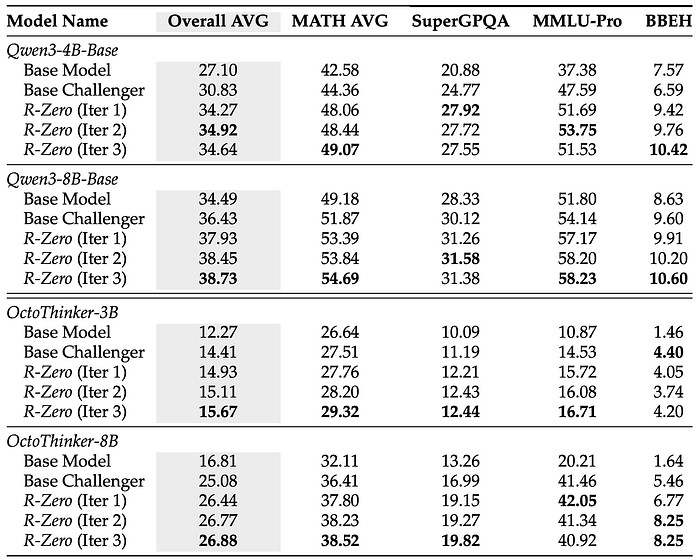
The paper's ablation studies further confirm that every component is critical. Removing the Challenger's RL training, the repetition penalty, or the task filtering all lead to significant performance degradation, validating the thoughtful design of the framework.
The Road Ahead: Is R-Zero the Spark of Autonomous Superintelligence?
R-Zero is a profound and exciting development. It demonstrates a viable path toward AI systems that can improve themselves without being tethered to human-generated data. However, the authors are also clear about the limitations, which point to the next frontiers of research.
The Challenge of Subjectivity: The current framework excels in domains like mathematics where correctness is objective and can be reasonably approximated by a majority vote. Extending this self-play paradigm to subjective, open-ended tasks like generating creative poetry, writing a compelling legal argument, or having a nuanced dialogue remains a monumental challenge. What is the "majority vote" on a beautiful metaphor?
The Bottleneck of Pseudo-Label Accuracy: The paper courageously highlights a critical trade-off. As the Challenger generates progressively harder questions, the Solver's ability to produce a reliable majority-voted "ground truth" begins to decline. In their analysis, the true accuracy of the pseudo-labels dropped from 79% in the first iteration to 63% by the third. This decaying signal is a potential bottleneck that could limit the framework's ultimate performance ceiling. Finding more robust, self-correcting verification methods will be key to achieving unbounded evolution.
Despite these challenges, the implications of R-Zero are vast. It could revolutionize how we train AI, shifting focus from massive data collection to designing more sophisticated self-improvement architectures. Could future AI systems be launched with a "base" model that then evolves specialized skills for science, medicine, or engineering on its own, discovering strategies far beyond our current understanding?
R-Zero may not be the final destination, but it feels like a definitive step into a new era of AI development. It's a move away from simply scaling up old methods and a leap toward creating genuinely autonomous, self-evolving intelligence. The question it leaves us with is a thrilling one: what will an AI learn when it's finally free to write its own curriculum?
Key Takeaways
- Breaking the Data Bottleneck: R-Zero is a fully autonomous framework that enables LLMs to improve their reasoning skills without any human-curated data, tackling a key limitation for future AI.
- Co-Evolutionary Self-Play: The system uses two models, a "Challenger" and a "Solver," that co-evolve. The Challenger creates difficult tasks, and the Solver learns to solve them, creating an endless, self-improving curriculum.
- Ingenious Reward Mechanisms: The framework uses an "uncertainty reward" to guide the Challenger to create tasks at the perfect difficulty and "majority vote" to create reliable pseudo-labels for the Solver to learn from.
- Proven Performance and Generalization: R-Zero delivered significant boosts on both math and general reasoning benchmarks, showing that the skills it learns are fundamental and transferable.
- A New Paradigm: While challenges remain, especially in subjective domains, R-Zero represents a major step towards truly autonomous AI systems that can learn and grow beyond the scope of human knowledge.
References
Huang, C., Yu, W., Wang, X., et al. (2025). R-Zero: Self-Evolving Reasoning LLM from Zero Data. arXiv:2508.05004.