

This, is an era of Large Language Models, an era of generative AI, and literally on daily basis, a new technology emerges up and damn are we in for a treat!
People who are passionate about Artificial Intelligence, machine Learning, deep learning, and related architectures, all of these people, their time is now. This is the era. And I am beyond elated, interested, and joyful too, to be able to understand all these new techs coming up, embrace it, and actually try to reduce this complex domain into bits for myself to learn, and for all of the readers.
Large Language Models are not just machines that talk — they are mirrors reflecting the structure and nuance of human thought
This article is actually an extension of my previous two works:
Generative AI: Shaping the Future of Creativity and Innovation
Large Language Models — The Greater Impact
In these two articles, I have almost written everything about LLMs, from start to end, but this article today is an even further extension of it. In these two articles, I have talked about types, new age tools, AI integration, structure, encoders, and almost everything, to be honest. But let's continue with our today's discussion.
First, I will start by stating the most important protocols, or techniques, you can say in the LLM industry, or how the core is basically structured.
Chain-of-Thought (CoT) Reasoning
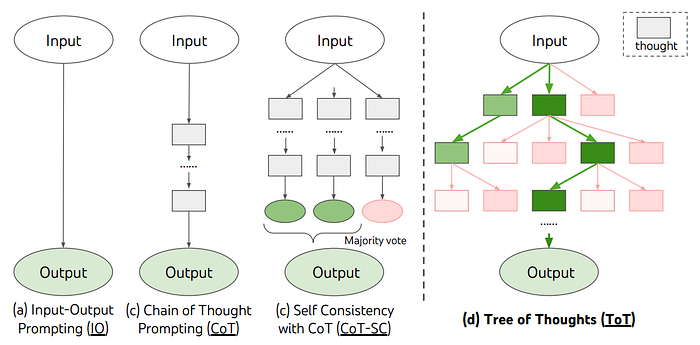
The Chain-of-Thought (CoT) Reasoning Protocol focuses on encouraging LLMs to break down complex problems into intermediate reasoning steps. This mimics human-like logical reasoning, where the model doesn't just give an answer but provides a sequence of thoughts leading to the solution.
Key Features:
- Step-by-step reasoning
- Enhanced performance on complex tasks like arithmetic, puzzles, and logical problems
- Generates intermediate steps, improving accuracy and interpretability
Code Example
openai.api_key = 'your-openai-api-key'
prompt = """
Let's solve the following problem step by step:
What is 15 * 14?
Step 1: Break the multiplication into smaller, manageable parts and reason about it.
"""
response = openai.Completion.create(
engine="gpt-3.5-turbo",
prompt=prompt,
max_tokens=150
)
print(response.choices[0].text.strip())Retrieval-Augmented Generation (RAG)
The Retrieval-Augmented Generation (RAG) Protocol combines a retrieval mechanism with generative capabilities. It enables models to retrieve relevant information from external sources, such as knowledge bases or the web, to enhance their generation quality. This method significantly improves model accuracy by leveraging real-time or external data.
Key Features:
- Efficient retrieval using vector-based search techniques
- Generates responses based on retrieved documents
- Ideal for tasks requiring up-to-date knowledge and external data
Code Example:
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq")
generator = RagSequenceForGeneration.from_pretrained("facebook/rag-token-nq")
question = "Who was Albert Einstein?"
inputs = tokenizer(question, return_tensors="pt")
retrieved_docs = retriever.retrieve(inputs['input_ids'])
generated_answer = generator.generate(inputs['input_ids'], retrieved_docs['doc_ids'])
answer = tokenizer.decode(generated_answer[0], skip_special_tokens=True)
print(answer)LOTUS (Low-Rank Transformers)
LOTUS (Low-Rank Transformers) is a computational efficiency protocol designed to reduce the time and resources required for the self-attention mechanism in transformer models. By approximating the attention matrix with a low-rank decomposition, it makes large transformer models more efficient without sacrificing much performance.
Key Features:
- Reduces attention complexity from quadratic to linear or near-linear
- Makes large-scale models computationally feasible
- Focuses on approximating the attention matrix with low-rank decompositions
Code Example:
import torch
import torch.nn as nn
class LowRankAttention(nn.Module):
def __init__(self, dim, rank):
super().__init__()
self.dim = dim
self.rank = rank
self.W1 = nn.Parameter(torch.randn(dim, rank))
self.W2 = nn.Parameter(torch.randn(rank, dim))
def forward(self, query, key, value):
Q = query @ self.W1
K = key @ self.W1
V = value @ self.W2
attention_weights = torch.softmax(Q @ K.transpose(-2, -1) / self.dim ** 0.5, dim=-1)
return attention_weights @ V
model = LowRankAttention(512, 8)
query = torch.randn(10, 20, 512)
key = torch.randn(10, 20, 512)
value = torch.randn(10, 20, 512)
output = model(query, key, value)
print(output.shape)Few-Shot Learning
Few-shot learning enables models to generalize from a limited number of labeled examples. By using minimal training data, LLMs can still perform well on new tasks. This is an essential protocol for real-world applications where data is often sparse or expensive to collect.
Key Features:
- Learns from only a few labeled examples
- Enables LLMs to quickly adapt to new tasks
- Reduces the need for large-scale labeled datasets
Code Example:
openai.api_key = 'your-api-key'
prompt = """
Translate the following English sentences into French:
- How are you?
- What is your name?
- I love programming.
Answer:
"""
response = openai.Completion.create(
engine="gpt-3.5-turbo",
prompt=prompt,
max_tokens=60
)
print(response.choices[0].text.strip())Prompt Engineering
Prompt engineering involves designing inputs to guide the model towards producing optimal outputs. This protocol focuses on how to structure and phrase prompts to enhance model performance across a range of tasks like classification, summarization, and translation.
Key Features:
- Customizing inputs to improve output quality
- Strategies like zero-shot, one-shot, and few-shot prompting
- Essential for tasks that require high precision or specialized knowledge
Code Example:
openai.api_key = 'your-openai-api-key'
prompt = """
Translate the following English sentences into French:
- How are you?
- What is your name?
- I love programming.
Answer:
"""
response = openai.Completion.create(
engine="gpt-3.5-turbo",
prompt=prompt,
max_tokens=60
)
print(response.choices[0].text.strip())Multimodal LLMs
Multimodal LLMs combine different forms of input data, such as text, images, and audio, to perform tasks that require understanding across these modalities.
Multimodal models are designed to understand and generate outputs across different types of data, like text, images, and sound. These models are essential for tasks that require cross-domain knowledge, such as image captioning, text-to-image generation, or speech-to-text.
In multimodal LLMs, a unified architecture is used to process inputs from different domains and integrate them into a shared latent space. This allows the model to better understand and reason about tasks that span multiple modalities.
Code Example:
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import requests
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch16")
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch16")
# Load image
image = Image.open(requests.get("https://example.com/image.jpg", stream=True).raw)
# Encode text and image
inputs = processor(text=["a photo of a cat"], images=image, return_tensors="pt", padding=True)
# Get similarity between text and image
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
probs = logits_per_image.softmax(dim=1) # probabilities of image matching text
print(probs)Model Context Protocol (MCP)
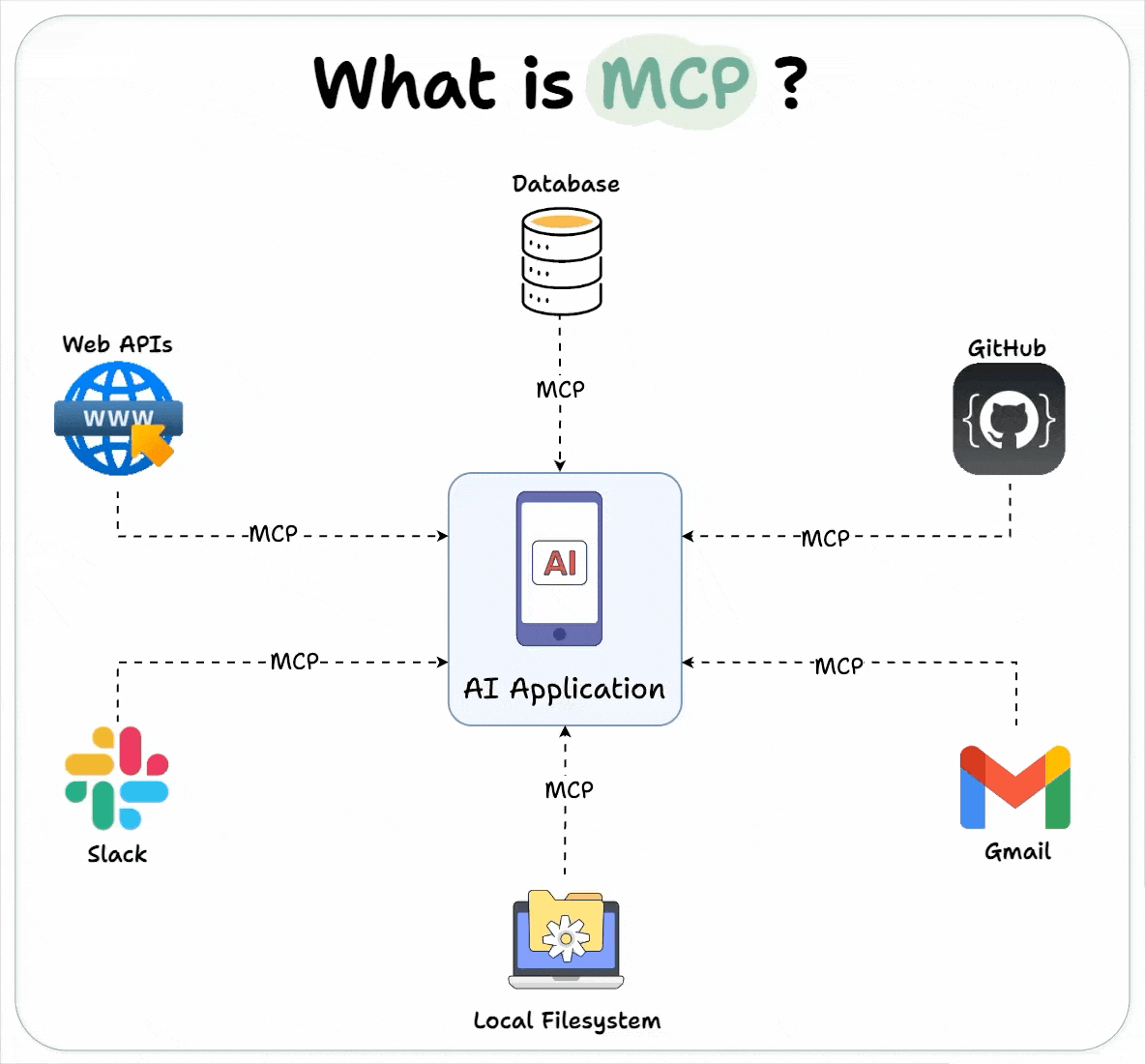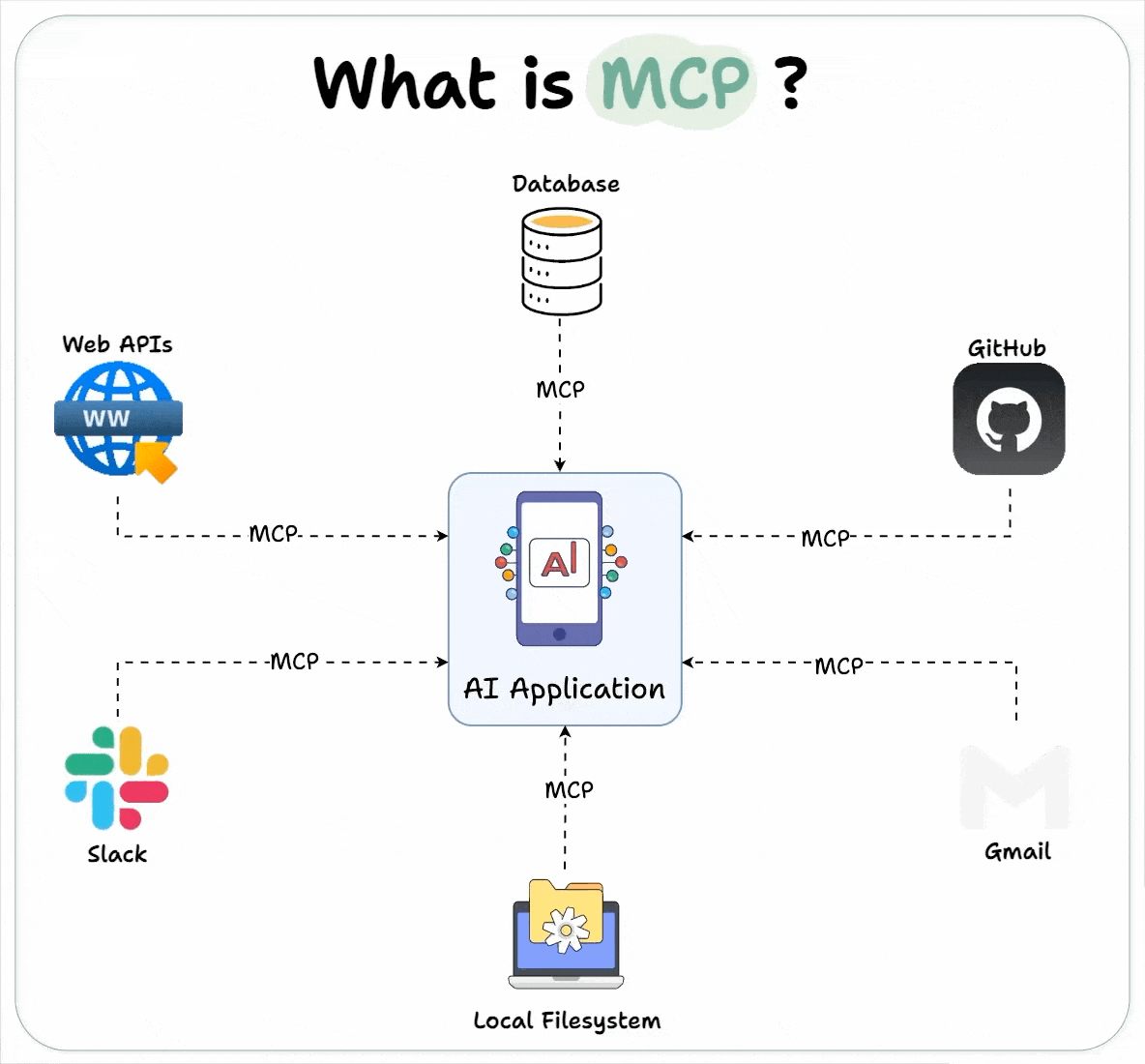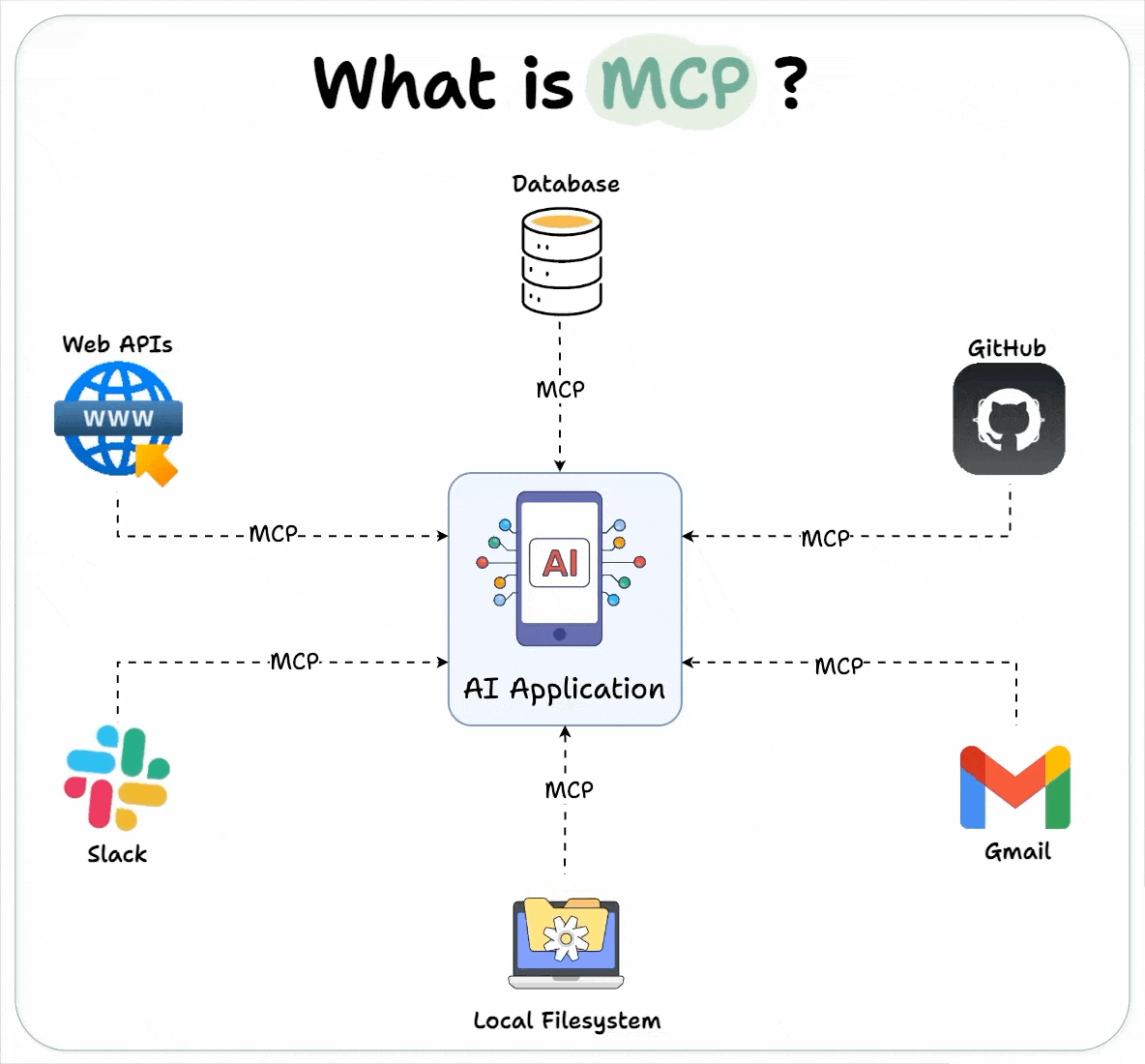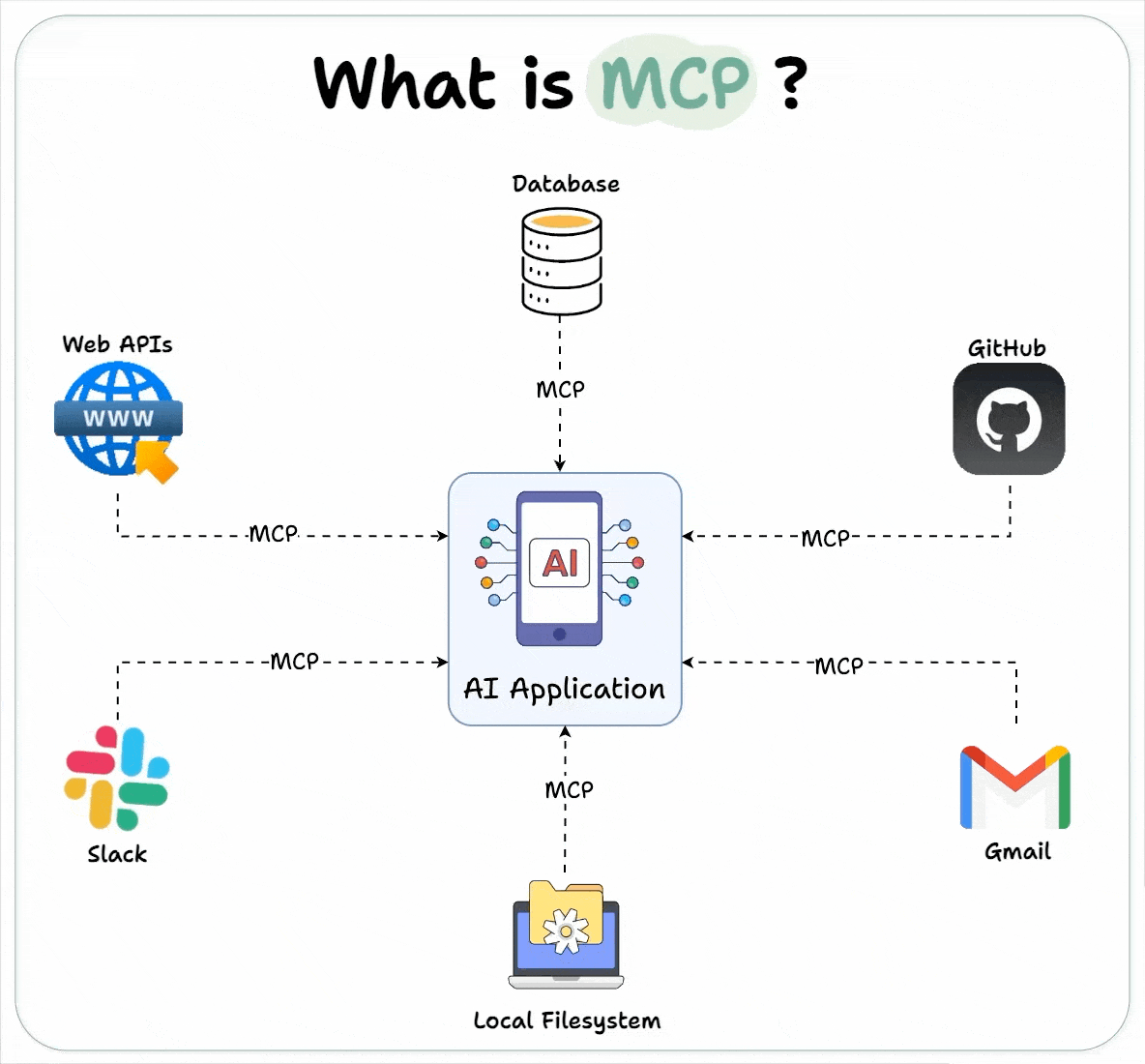
The Model Context Protocol (MCP) focuses on how a model maintains, updates, and utilizes context throughout an interaction or task. This protocol allows models to handle more complex and detailed inputs, improve the generation quality by considering prior context, and manage memory over longer sessions or data spans.
The primary challenge that MCP addresses is the forgetting problem, where a model may struggle to recall important information across long conversations or documents. MCP solves this by enabling the model to better retain and utilize past interactions or large input text, allowing for more coherent and relevant outputs.
The MCP has evolved alongside architectures like Transformers, which suffer from quadratic complexity in attention mechanisms, making it challenging to retain context for very long sequences of tokens. By using smarter techniques, like memory-augmented networks or attention optimization, MCP improves long-range context handling.
Key Features of MCP
- Context Preservation: The model retains relevant context across multiple interactions or long inputs, ensuring that the output stays consistent and connected.
- Memory Integration: The model can leverage external or internal memory banks to store and access prior context.
- Token Efficiency: Optimized strategies for selecting and storing tokens that are most relevant, reducing the overhead of storing unnecessary context.
- Attention Optimization: Techniques like sparse attention or long-range attention mechanisms help the model focus on important parts of the context.
MCP Techniques
- Contextual Memory Networks: Models can dynamically store and retrieve context throughout interactions. This allows the model to "remember" crucial elements of past conversations and improve coherence, particularly in dialogue systems.
- Retrieval-Enhanced Memory: A combination of retrieval-augmented generation (RAG) and MCP allows the model to fetch relevant pieces of information from external databases or stored memory to keep the response aligned with earlier context.
- Hierarchical Contextualization: For tasks that require multi-step reasoning, hierarchical memory structures can be used to organize context by layers, making it easier for the model to handle long-term dependencies.
- Dynamic Attention: Instead of attending to the entire input sequence, the model focuses on the most relevant tokens in the context, reducing the computational load and improving speed without sacrificing context.
- Long-Range Contextual Attention: Optimizations in the attention mechanism, such as Linformer or Longformer, provide scalable solutions to maintaining context over long sequences, addressing the limitations of vanilla transformers.
Code Example for MCP Integration
Below is a simplified example of how the Model Context Protocol could be integrated with a transformer-based model to manage context dynamically over multiple steps. The example is based on Hugging Face's Transformers library:
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# Initialize tokenizer and model
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
# Initialize context memory
context_memory = []
def update_context_memory(new_text):
# Update context with new input
context_memory.append(new_text)
def generate_response():
# Join context into a single input string for model processing
input_context = " ".join(context_memory)
input_ids = tokenizer.encode(input_context, return_tensors="pt")
# Generate model output based on the current context
output = model.generate(input_ids, max_length=100, num_return_sequences=1, no_repeat_ngram_size=2)
response = tokenizer.decode(output[0], skip_special_tokens=True)
return response
# Example: Adding context to memory
update_context_memory("Hello, how are you?")
update_context_memory("What is the weather like today?")
# Generate a response based on the context
response = generate_response()
print(response)Applications of MCP
- Dialogue Systems: In chatbots or virtual assistants, MCP ensures the model can maintain coherent conversations and remember prior exchanges.
- Document Summarization: Long documents or articles can be effectively summarized by the model, retaining crucial points and ensuring the summary is consistent with the document's structure.
- Long-form Content Creation: When generating stories, reports, or essays, MCP allows the model to remember previous sections and keep the content connected and logical.
The Model Context Protocol is a critical innovation for improving the efficiency and quality of LLMs, especially when dealing with long-term interactions or complex tasks. It focuses on preserving and managing context dynamically, ensuring that models stay relevant and coherent over time. While challenges like scalability and memory management remain, the continuous improvement of architectures and techniques is making MCP increasingly effective for a range of applications.
Comparison Parameters
Now, let's go beyond those techniques or protocols. Here are some parameters through which we can define or check the different LLMs as to which is better, which is not so much.
Model Efficiency and Optimization
- Distillation: You could discuss how distillation is used to create smaller, more efficient versions of LLMs while retaining performance. This is important for deployment in real-world applications where computational resources may be limited.
- Quantization: A technique used to reduce the size of models by representing weights with lower precision, making them easier to deploy on edge devices without sacrificing much accuracy.
Example Topic: Efficient Deployment of LLMs: From Large to Small Without Losing Power
Fine-Tuning on Domain-Specific Data
- Domain-Specific Adaptation: While LLMs are pre-trained on vast corpora, fine-tuning them on domain-specific data can significantly improve performance. For example, fine-tuning a language model on legal documents to perform well in legal language tasks.
- Adapters: Instead of full retraining, adapter layers allow LLMs to be fine-tuned for specific tasks without altering the original model architecture.
Example Topic: Fine-Tuning for Specialized Tasks: Adapting LLMs for Healthcare, Law, or Finance
Model Explainability and Interpretability
- Explainable AI: Discuss methods for improving the interpretability of LLMs, like SHAP (Shapley Additive Explanations), LIME (Local Interpretable Model-agnostic Explanations), or visualizing attention weights. These methods help understand why a model made a certain prediction or generated a specific output.
- Attention Visualization: For transformer-based models, understanding the attention mechanism can provide insights into what the model focuses on during reasoning or text generation.
Example Topic: Understanding How LLMs Think: Interpretability and Explainability in Modern AI Models
Emerging LLM Architectures
Emerging architectures for Large Language Models (LLMs) are reshaping the landscape of AI, enabling greater efficiency, scalability, and specialized performance in various domains. As LLMs grow in size and complexity, researchers are increasingly focusing on ways to optimize these models, make them more adaptable, and improve their overall performance.
Mixture of Experts
Mixture of Experts, or MoE, is a new approach in building large language models that makes them more efficient and powerful. Instead of using the entire neural network for every task, MoE activates only a few parts of the model — called "experts" — based on what the input requires. Think of it like a team of specialists where only the right people are called in to handle a particular problem. This allows the model to grow much larger, with billions or even trillions of parameters, without needing massive computing power for every single input. The selection of which expert to use is controlled by something called a gating mechanism, which routes the data to the best-suited expert. The idea is similar to how our brain uses different regions for different tasks — only the necessary parts get activated. MoE models are especially useful in multitask settings or when dealing with different languages, as certain experts can specialize in specific areas. Google and other research labs have built large models using this technique, such as GShard and GLaM, which showed better performance than traditional dense models while using fewer computational resources. However, this system isn't perfect. Training can be tricky because the model needs to learn how to pick the right experts consistently. Sometimes, a few experts end up doing most of the work, which can lead to imbalances in learning. It also requires careful software design and can be harder to run efficiently on regular computer hardware. Despite these issues, Mixture of Experts is seen as a major step forward because it allows artificial intelligence systems to become smarter and more capable without becoming impossibly expensive to train and run. By enabling large models to be both modular and efficient, MoE is paving the way for more intelligent and flexible AI systems in the future.
Switch Transformers
Switch Transformers are a special kind of Mixture of Experts model that take the idea of efficiency even further. Instead of using several experts for each input, a Switch Transformer uses only one expert per token, which drastically cuts down on the amount of computation needed. Introduced by Google Research, this method replaces the standard feedforward part of a transformer model with multiple parallel expert networks and then uses a router to decide which one should handle each piece of the input. The simplicity of choosing just one expert per token makes the model easier to scale and faster to train, even when it has hundreds of billions of parameters. This means researchers can build incredibly large models that are still practical to run. What makes Switch Transformers special is that they keep the benefits of being very large and capable, without overwhelming the computer systems that train or use them. They've been shown to perform better than regular dense models when comparing how much performance you get for each unit of computing power used. That said, Switch Transformers also come with challenges. If the router doesn't assign tokens well, the model might not learn effectively. There's also the issue of some experts getting used much more than others, which can slow down or weaken the training process. Engineers have developed solutions like balancing mechanisms to help fix these problems. Another limitation is that not all hardware is good at handling sparse activations, which is how these models run so efficiently. Even with these challenges, Switch Transformers are seen as a major innovation in the world of artificial intelligence. They show that it's possible to build smarter, faster, and more efficient language models by using a smarter design, not just more power.
Efficient Transformers (e.g., Longformer, Linformer)
Efficient Transformers are designed to optimize the self-attention mechanism for long sequences of text. Standard transformers have quadratic time complexity in terms of the input length, which limits their ability to scale to long documents. Efficient transformers, like Longformer and Linformer, reduce this complexity by employing sparse attention mechanisms or low-rank approximations.
Key Benefits:
- Long-Range Attention: These models can process longer sequences while maintaining reasonable computation times.
- Scalable: Suitable for use cases involving long documents or sequences where traditional transformers struggle.
Example:
- Longformer uses sliding window attention, enabling efficient processing of long documents by attending only to a local context instead of the entire sequence.
- Linformer reduces the attention matrix by approximating it with low-rank matrices, enabling faster training for long sequences.
Recurrent Transformers
While transformers are known for their non-recurrent, parallelizable architecture, researchers are looking at hybrid architectures that incorporate recurrent elements to enhance long-term memory. Recurrent Transformers blend the strengths of both RNNs (for maintaining long-term context) and Transformers (for fast computation and parallelism).
Key Benefits:
- Memory Augmentation: Recurrent transformers are designed to handle long-term dependencies more effectively.
- Improved Performance on Sequential Tasks: These architectures are particularly useful for tasks that require both long-term memory and fast processing, such as time-series prediction and sequential decision-making.
Example:
- Reformer is a hybrid model that uses both transformers and RNNs to process long sequences. It combines local attention with efficient recurrent memory to scale effectively for very long texts.
Vision Transformers (ViT)
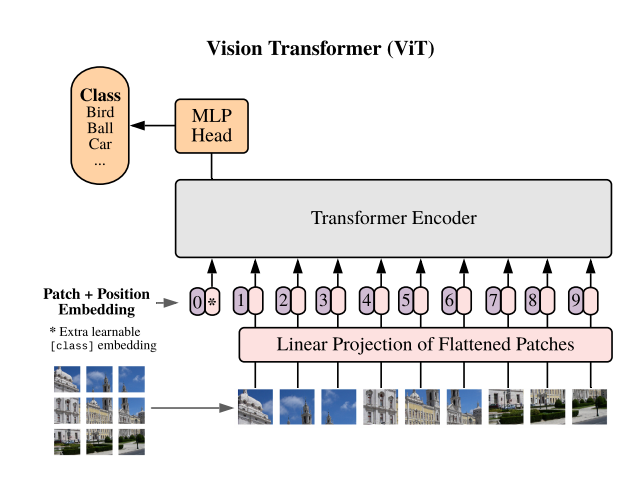
While transformers are traditionally used for NLP, their application is expanding to vision tasks. Vision Transformers (ViT) have demonstrated that transformers can outperform CNNs in image classification tasks by treating image patches as tokens and applying transformer attention to capture relationships across patches.
Key Benefits:
- Scalable: ViTs can handle larger datasets and more complex relationships than traditional convolutional architectures.
- Unified Architecture: Unlike CNNs, ViTs do not rely on convolution layers, making them more adaptable to different kinds of input data.
Transfer Learning in LLMs
- Zero-Shot and Few-Shot Learning: These techniques allow LLMs to perform tasks with little or no task-specific data, making them highly versatile across different domains.
- Cross-lingual Models: Explore how LLMs can handle multiple languages and the concept of cross-lingual transfer learning, which allows a model to generalize tasks across different languages with minimal additional training.
Artificial General Intelligence (AGI)
Artificial General Intelligence (AGI) refers to AI systems that exhibit human-like cognitive abilities across a wide range of tasks. Unlike narrow AI systems (which are designed to perform specific tasks like language translation, image recognition, etc.), AGI systems would be capable of performing any intellectual task that a human can do, exhibiting the ability to reason, learn, adapt, and understand across diverse domains.
While current AI systems, like LLMs, excel in specific tasks (e.g., language generation), they are still considered narrow AI because they lack generalization abilities and adaptability beyond their training scope. AGI remains a theoretical concept at this point, but its pursuit is central to advancing AI technology.
Key Characteristics of AGI
- Autonomy: AGI systems would be able to perform tasks independently, requiring minimal human intervention.
- Generalization: AGI can transfer knowledge learned in one domain to completely different tasks, similar to how humans can apply their skills to new situations.
- Reasoning and Problem Solving: An AGI would be capable of abstract reasoning, making decisions based on incomplete or contradictory information, and solving novel problems.
- Consciousness: While still a matter of philosophical debate, some definitions of AGI involve creating systems that have a form of self-awareness or consciousness.
Current Approaches Toward AGI
- Cognitive Architectures: Cognitive architectures like ACT-R and Soar aim to simulate human cognitive processes and serve as a foundation for AGI.
- Neuroscience-Inspired Models: Many AGI researchers look to the brain for inspiration, developing neural architectures that mimic the structure and functioning of human neurons.
- Reinforcement Learning (RL) and Self-Supervised Learning: These approaches are often considered promising paths toward achieving AGI because they focus on learning from interaction and the environment, which is more flexible than supervised learning.
The Future of LLMs and AGI
- Artificial General Intelligence (AGI): LLMs are seen as one of the foundational building blocks toward achieving AGI. You could discuss how these models are stepping stones toward more generalized, adaptive AI systems.
- Self-Supervised Learning: The next frontier for LLMs may be self-supervised learning, where models can generate their own training data from unstructured inputs like text, images, and videos.
Example Topic: From LLMs to AGI: Exploring the Road Ahead and the Role of Self-Supervised Learning
Emerging architectures in LLMs and the quest for AGI are two areas of active research that will likely drive the future of artificial intelligence. While LLMs and their variants like MoE, Switch Transformers, and Vision Transformers open up powerful applications, AGI promises to push the boundaries of machine intelligence, one day leading to systems that can think, reason, and act like humans across all domains.
Top 10 Notebook LLM Tools in 2025
1. NotebookLM by Google
2. Claude by Anthropic
3. Cursor
4. Notion AI
5. Jupyter AI
6. Replit Ghostwriter
8. Kite
9. GitHub Copilot
10. IntelliCode
Bonus: Perplexity

Perplexity.ai is a smart, AI-powered tool that combines the best of a search engine and a chatbot. Unlike traditional search engines that just give you a list of links, Perplexity answers your questions directly and clearly, while also showing you where the information comes from. Every response includes citations to real sources like news articles, research papers, or trusted websites, so you can click and verify the facts yourself. It's great for getting quick, reliable answers on almost any topic.
What makes it even more useful is its conversational style. You can ask follow-up questions, and it remembers the context, so you don't have to rephrase everything. This makes it feel more like chatting with a knowledgeable assistant than searching the web. It's available as a website, a mobile app, and even a browser extension, so you can use it wherever and whenever you need.
Whether you're doing academic research, comparing tech products, or just curious about something in the news, Perplexity gives you fast, trustworthy answers. It's especially helpful when you want both AI intelligence and human-level clarity, with the added bonus of real-time web access. Overall, it's like Google and ChatGPT rolled into one powerful assistant.
Conclusion
Large Language models are now just a part of our daily lives; it is our literal solution. A very recent trend of Ghibli art is just one of the few examples of how Gen-AI and LLMs can drive all of humanity crazy. While NVIDIA is trying to revamp its GPUs and build a sustainable future, there is no denying that all of these tools might be unethical. All of us in one way or another have surrendered to AI in today's life, but with all that said, if we use it wisely, there is surely an increase in jobs, the industry is going to be at never-seen heights, and our work is destined to be easier. One of my mentors recently told me that, either day, no tool that doesn't have Gen-AI capabilities can enter the industry now, and that speaks volumes to the tech we are playing with today. Beware, and most importantly, be wise.
On that note, I will end this big article, and I believe amongst all three articles I have written about LLMs and Gen-AI, this is pretty much about it.
Keep learning, keep growing!
Until next time, keep your head up and keep moving forward!!!