

This Saturday, Meta didn't just make an announcement, they detonated a bomb in the world of AI.
LLaMA 4 has arrived, and with it comes something that was once unthinkable: A 10 million token context window.
That's not evolution. That's revolution.
And if you're wondering why it dropped on a Saturday? zuck's reply?
Sometimes innovation doesn't wait for Monday morning meetings. It moves when the work is done, and LLaMA 4 was ready to move the world.
Welcome to the Near-Infinite Context Era
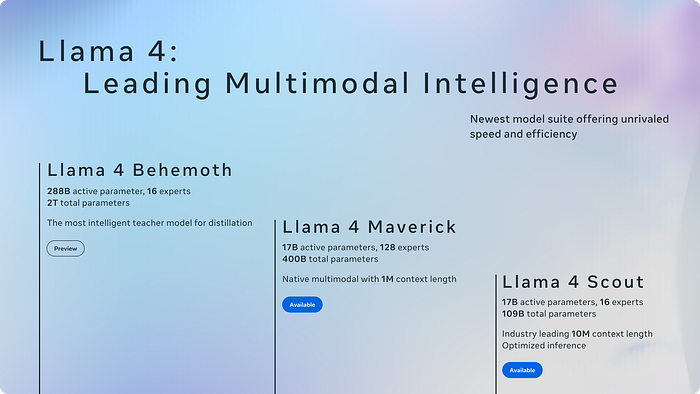
In a bold move that's set the AI world ablaze, Meta has unleashed not one, not two, but three titanic models, each built for a future where boundaries are a thing of the past:
- LLaMA 4 Scout (smallest, if you can call 109B parameters "small")
- LLaMA 4 Maverick (mid-tier powerhouse)
- LLaMA 4 Behemoth (a literal 2 trillion parameter giant still baking in the oven)
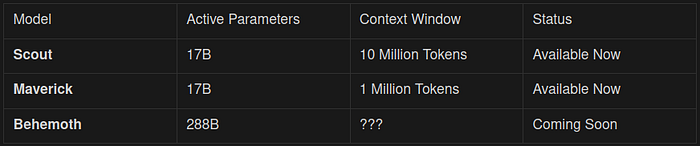
But here's what really cracked open our collective jaws: 10 million token context window for Scout.
Yes, you read that right. Ten. Million. Tokens. Compared to the previous frontier (2M tokens from Gemini), this feels like swapping a garden hose for Niagara Falls.
Meta is calling it "near-infinite context." For anyone building AI agents, researching long documents, or dreaming of truly intelligent personal assistants, the age of forgetting is officially ending.
Multimodal, Multi-Expert, and Monumental
All three LLaMA 4 models are natively multimodal, meaning they can handle text, images, video, and other modalities effortlessly.
Even more fascinating: Meta went full throttle on Mixture of Experts (MoE architecture. Think of it like a team of specialists inside the AI's brain, each expert picking the right piece of knowledge at the right time.
- Scout: 16 experts, 17B active parameters.
- Maverick: 128 experts, 17B active parameters.
- Behemoth: 16 experts but 288B active parameters, a true frontier model.
These models are optimized to the core, even using FP8 precision for ultra-efficient training across 32,000 GPUs.
And they're fast. 390 Tflops per GPU fast.
Scout vs. Maverick vs. Behemoth: What's Cooking?
Scout isn't just about crazy memory, it's also crushing previous multimodal benchmarks, outperforming competitors like Gemini 2.0 Flashlight, Mistral 3.1, and more.
Maverick, meanwhile, sits comfortably as the #2 chat model (based on ELO scores), beating out Gemini and Deepseek V3 in reasoning and coding, at half the active parameters and a fraction of the cost.
And Behemoth? It's rumored to outperform GPT-4.5 and Claude Sonnet on STEM tasks, and it's not even out yet.
Hold onto your llamas, folks. The reasoning model is coming soon.
You can download the available models from Meta's official site or Hugging Face.
The End of Context Limits (and Maybe the Beginning of Reasoning)
The numbers alone are mind-bending, but the implications are even bigger.
✅ Read and analyze massive research reports ✅ Train AI agents with vast memory ✅ Ask complex, layered questions across hours of video or mountains of text ✅ Build autonomous workers that don't forget their instructions halfway through
Meta's nearly infinite memory isn't just a flex, it's a full-on breakthrough.
One Catch: Licensing Drama
Before you rush to plug these beasts into your apps, know this: Meta's licensing isn't truly open-source by the purest standards.
- If your company has 700M+ users, you'll need special permission.
- You must display a "Built with LLaMA" notice.
- You must include attribution in your projects.
It's not MIT license freedom, but for most builders, it's a small price to pay for access to models this revolutionary.
What This Means for the Future
We're entering an era where the limits of memory, modality, and understanding are being obliterated.
- Enterprise AI is about to level up, companies are already baking LLaMA 4 into powerful content management solutions.
- Open-weight models like Maverick are closing the gap with proprietary giants like GPT-4.
- Developers are getting the tools to build truly intelligent, truly limitless applications.
LLaMA 4 isn't just an upgrade. It's a rebellion against small thinking. It's a call to dream bigger.
The age of small context windows, narrow models, and AI with goldfish memories is over. And honestly? It's about time.
Liked this breakdown? Clap, share with your fellow AI enthusiasts, and stay tuned, because the llama revolution has only just begun.
Thank you for being a part of the community
Before you go:
- Be sure to clap and follow the writer ️👏️️
- Follow us: X | LinkedIn | YouTube | Newsletter | Podcast | Differ | Twitch
- Check out CoFeed, the smart way to stay up-to-date with the latest in tech 🧪
- Start your own free AI-powered blog on Differ 🚀
- Join our content creators community on Discord 🧑🏻💻
- For more content, visit plainenglish.io + stackademic.com