
Selamlar, bu yazıda aslında her biri başlı başına geniş kavramlardan oluşan bir konsepti, birbiri ile ilişkilendirip bağlayıcı bir akış çıkarmaya gayret ettim. Bu yüzden her kavramı detaylı bir şekilde açıklamak konu bütünlüğüne ve okuma kolaylığına mani olabileceğinden, yazı sırasında bahsi geçen kimi kavramların detaylı bilgilerine ulaşmak isteyenler için kaynakça bölümü faydalı olacaktır.
-Array-based veri yapılarının nasıl çalıştığını, "bitişik bellek" (contiguous memory) ve "capacity" kavramını, ekleme/çıkarma sırasında ortaya çıkan bellek maliyetlerini,
-Hash-based yapılarda hash fonksiyonları, çakışma yönetimi (collision) ve ortalama O(1) erişimin sağlandığı mantığı,
-Tek makine üzerinde veritabanı join'lerinde veya key–value aramalarında çok faydalı olan hash tabloların maliyet ve sınırlamalarını,
-Dağıtık sistemlerde verinin sharding (parçalama) yaklaşımıyla dağıtılmasını, basit mod yaklaşımının sorunu ve consistent hashing çözümünü
neden sonuç ilişkileriyle irdelemeye çalıştım.
Devam niteliği taşımasa da, bu yazıyı okumadan önce yine basit bir şekilde ele aldığım Big O Notasyonu ile alakalı bu yazıya bir göz atmak kimileri için faydalı olabilir.
Veri yapıları performans, ölçeklenebilirlik, sürdürülebilirlik ve bu gibi birçok kavram açısından kritik bir role sahiptir. Özellikle büyük veri hacmi veya yüksek trafikli uygulamalar söz konusu olduğunda, seçtiğimiz veri yapısı her işlemde katlanarak büyüyen maliyetler doğurabilir.
Bu nedenle, array-based ve hash-based yapıların temellerini incelemenin, yazının devamında bahsedeceğim kavramları daha iyi açıklayabilmek açısından önemli olduğunu düşünüyorum.
array-based dediğimde, burada özellikle dinamik array (C# List<T> gibi) yaklaşımından bahsettiğimi vurgulamak isterim. Array tabanlı veri yapıları aslında circular queue, deque, sabit boyutlu array gibi çok farklı tasarımlara da sahip olabilir.
1)Array-Based (Dinamik Array) Mantığı ve Bellek Kullanımı
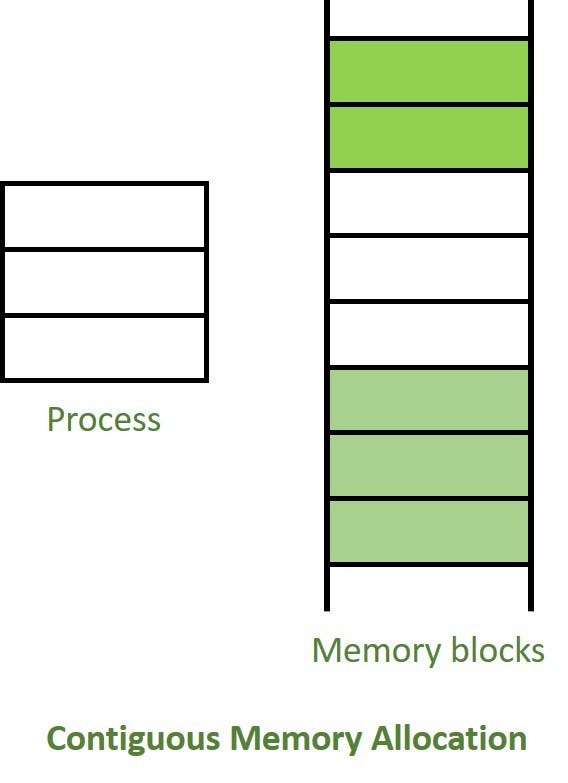
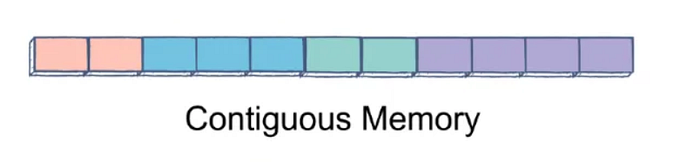
-Bitişik (Contiguous) Bellek ve capacity
C# List<T>, alt seviyede(under the hood) bir array kullanır. Elemanlar bellekte art arda (bitişik) durur. Bu bize ne sağlar noktasında ise;
- Rastgele erişim (index-based) O(1), İndekse göre "base address (dizinin bellekte başladığı yer,ilk elemanın konumu) + (index * elementSize)" hesaplanır, belleğe atlanır(memory jump).
Burayı daha açıklayıcı ifade etmek gerekirse : Bellekte elemanlar bitişik (contiguous) yerleştirildiğinden, CPU aralarda başka veri yapılarıyla veya pointer'larla uğraşmadan doğrudan "index * elementSize" offset'ini ekleyip hedef adrese "atlayabilir." Yani ilgili bellek konumuna tek adımda gitmiş olur.
"Index" = Hangi elemanı istiyoruz , "elementSize" = Her eleman bellekte kaç bayt , "base address" = Dizinin ilk elemanının konumu
Bir örnek üzerinden de simüle edelim :
Diyelim ki bellekte 4 elemanlı bir array var. Elemanlar 10,20,30,40 olsun.Her elemanın (örneğin int tipi) 4 bayt yer kapladığını varsayalım. Bellek adresleri ise sırasıyla:
base address = 0x1000 (dizinin ilk elemanının başlangıç konumu)
eleman (index 0) → 10 → 0x1000 (fiziksel adres)
eleman (index 1) → 20 → 0x1004
eleman (index 2) → 30 → 0x1008
eleman (index 3) → 40 → 0x100C
index 2'ye erişmek istediğimizde, index (=2) ve base address (=0x1000) ile "elementSize" (=4 bayt) kullanarak, 0x1000 + (2*4) = 0x1008 adresine doğrudan atlanır. CPU burayı okuduğunda 30 değerini bulur.
-CPU cache dostu: Sıralı (sequential) işlem yaparken önbellek satırları (cache lines) ardışık elemanları getirir.
Ancak, "bitişik bellek" olmasının nedeni dizinin tek parça halinde yerleştirilmesidir (capacity). List<T>'in capacitysi dolunca:
- Genellikle mevcut kapasitenin iki katı büyüklüğünde yeni bir dizi oluşturulur ve veriler buraya kopyalanır (O(n) kopyalama maliyeti).
- Eski dizi serbest bırakılır ve gerektiğinde GC tarafından temizlenir.
Bu neden "maliyetli" olabilir?
-Büyük boyutlu listelerde yüksek rellocation (Her defasında O(n) kopyalama.)
-Kapladığı bellek (capacity) ile gerçek eleman sayısı (Count) aynı olmayabilir. Fazla capacity atıl kalırsa bellek israfına yol açabilir, yetersiz capacity varsa da sık reallocate söz konusu olur.
-Başa/Ortaya Ekleme: Dizinin bitişik yapısı gereği, ekleme yeri ile dizinin sonu arasındaki elemanları kaydırmak gerekir. 1 eleman ekleyince n eleman kayıyorsa bu O(n) maliyettir.
-Neden O(n), Çünkü bitişik dizide, ortadaki bir ekleme, gerideki her elemanın bellek adresini bir kademe sağa kaydırmak demektir.
Bunları bir kod örneği üzerinden açıklamak gerekirse :
public class ShoppingCart
{
public static void Main()
{
List<string> cart = new List<string>();
cart.Add("Laptop");
cart.Add("Mouse");
cart.Add("Keyboard");
// Ortaya ekleme (index=1) -> O(n)
cart.Insert(1, "USB Drive");
// Kaydırma: "Laptop" | "USB Drive" | "Mouse" | "Keyboard"
// Silme (index=2) -> O(n)
cart.RemoveAt(2);
// TrimExcess -> capacity'yi Count'a göre düşürür, O(n) kopyalama
cart.TrimExcess();
}
}"bitişik bellek" avantajı (sıralı erişim, CPU cache), dezavantajı (ortaya ekleme O(n), reallocate O(n)). Küçük/makul veri setlerinde ekleme sıklığı azsa amortize O(1) işleri gayet hızlıdır. Çok büyük veri veya sık ekleme-silme varsa gizli bir performans problemi haline gelebilir.
2)Hash-Based (Dictionary / Hash Table) Yapıları
array-based listelerin kapasite yönetimi ve ekleme-silme maliyetlerini irdeledik, ancak "key–value" bazlı aramalarda (OrderID->OrderDetails) tek tek diziyi taramak O(n) olacağına göre, daha hızlı (ortalama O(1) ) bir yöntem mümkün mü? İşte burada hash-based yaklaşım (C# Dictionary<TKey,TValue> gibi) devreye girer.
Hash Fonksiyonu ve Bucket Array
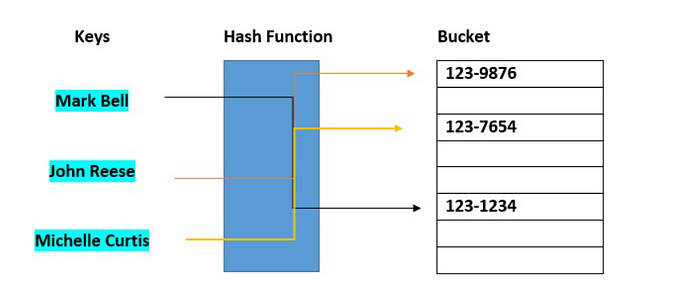
Bir hash table basitçe şu prensipte çalışır :
-Hash function: Key'i büyük bir tam sayı (hash(key)) olarak dönüştürür. ("BK1001" → 345678).
-Bucket array: Kapasitesi genelde 2'nin katıdır (8, 16, 32 vs.). "bucket index" = hash(key) mod capacity.
- Her bucket bir veriyi tutacak konumdur. Key "Ali" → hash("Ali") mod 16 = 13, "Ayşe" → 7 gibi.
Peki neden O(1) ?
- Sadece tek matematiksel işlem (mod) ve bir dizi erişimi.
- Çakışma (collision) azsa, o erişim sabit zaman sürer.
Şimdi collision kavramını açıklayarak devam edelim.
İki farklı key aynı bucket index değerine denk gelebilir (hash("BK1001") mod 16 = 7, hash("BK2004") mod 16 = 7). Bu durumda collasion ortaya çıkar.
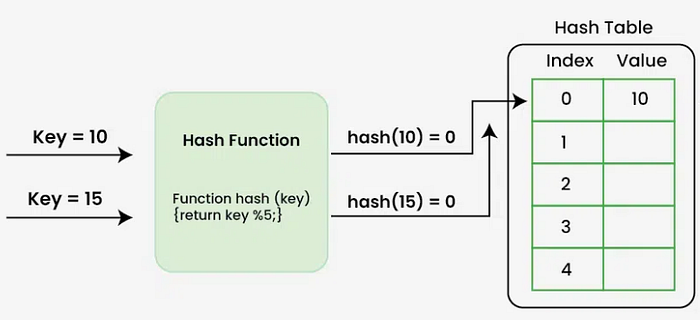
Bu durumu yönetmek için 2 ana yaklaşım vardır:
- Separate Chaining
- Open Addressing
yazının başında bahsettiğim gibi, bu yöntemleri detaylıca merak edenler için kaynakça bölümü yararlı olacaktır.
Biz bu yazıda separate chaining üzerinde duracağız. Ancak yine bu tekniği irdelemeden önce, daha iyi kavrayabilmek için linked list, non-contiguous memory allocation kavramlarını da basit bir şekilde ele almakta fayda var.
Bir linked list, her düğümün (node) veriyi (value) ve bir sonraki düğüme (next pointer/referans) işaretçiyi tuttuğu bir yapıdır.
Rastgele erişim (index-based) yoktur, bir düğüme ulaşmak için önceki düğümleri sırasıyla takip etmek gerekir. Bu nedenle arama O(n) kabul edilir.
Başa ekleme (head'e ekleme) her zaman O(1) sürede gerçekleşir çünkü yalnızca head pointer güncellenir. Sona ekleme ise tail pointer tutuluyorsa O(1) sürede tamamlanabilir. Ancak tail pointer yoksa, listenin sonuna ulaşmak için tüm düğümleri tek tek kontrol etmek gerekir, bu da O(n) zaman alır.
Bellek kullanım modeli: Her düğüm bellek içinde dağınık (noncontiguous) yerleşebilir; düğümleri birbirine next pointer'lar bağlar.
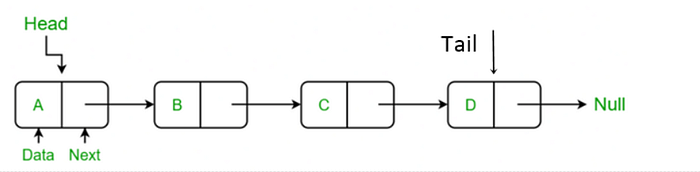
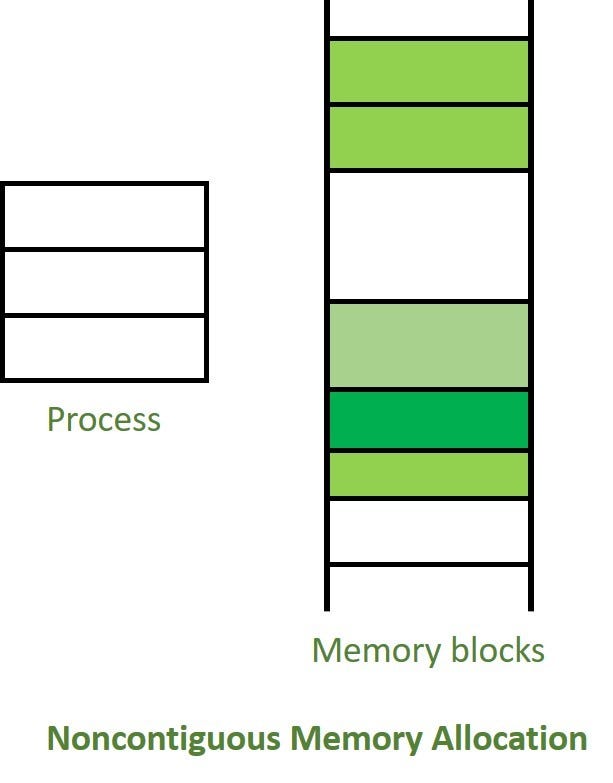
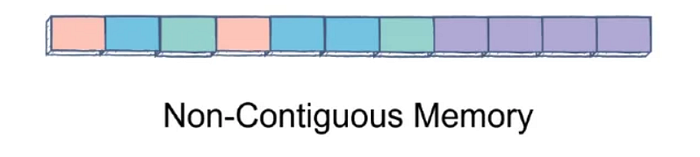
Bitişik (contiguous) memory dediğimiz array-based yapılarda elemanlar art arda adreslerde saklanırken, noncontiguous memory (bitişik olmayan) senaryoda her düğüm farklı bir bellek adresinde olabilir.
Linked list, tam da bu şekilde "her node istediği yerde durabilir, biz next pointer'ı ile bağlarız" yaklaşımıyla hareket eder.
Artık hash table collision yönetiminde separate chaining yaklaşımına geçiş yaparken bucket dizisinin her elemanının (bucket[i] gibi) linked list tutabileceği fikri daha çok anlam kazanmıştır umarım. Yani bu durumda biz, collision olunca yeni key'i linked list'in sonuna eklemek O(1) olduğu için ek overhead yaşamayız.
Şimdi bu kavramları nedenleriyle açıkladığımıza göre, separate chaining yaklaşımının uygulama prensibini basitçe ele alabiliriz :
-Bucket dizi elemanı, bir linked list (ya da mini tree) saklar.
-Collision varsa, aynı bucket'a gelen key–value'lar bu linked list sonuna eklenir.
-Arama/silme de bu listedeki az sayıda öğeyi karşılaştırarak yapılır.
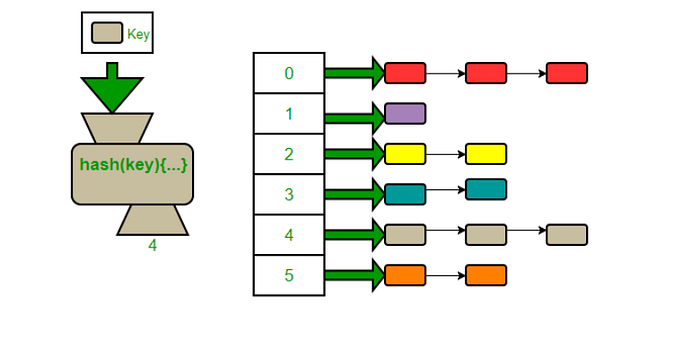
Hash Table'ların ortalama O(1) erişim özelliğini sürdürübilmesi, load-factor ve re-hash mekanizmalarının sağlıklı bir şekilde yönetilmesine bağlıdır. Eğer tablo aşırı dolar veya kötü bir hash function(key'lerin çoğunu aynı bucket index'e düşürmek gibi) kullanılırsa collision artar ve hash tablosunun performansı bozulabilir. Bu durumda, çakışmaları yöneten veri yapısına bağlı olarak, arama ve ekleme işlemlerinin zaman karmaşıklığı en kötü durumda O(n) olabilir. Bu yüzden, bucket array boyutu belirli bir eşiğin üstüne çıkıldığında yeniden büyütülür ve re-hash (tüm key'leri yeni dizinin ilgili konumlarına yerleştirme) yapılır.
Load Factor, Re-hash ve Performans
Bir hash table'da, "load factor = (eleman sayısı) / (bucket array capacity)". Örnek olarak 12 eleman, 16 capacity = 0.75 load factor sonucu elde edilir.
Load factor belirli bir eşiği (örnek 0.75) aştığında, kapasite 2 katı yapılır, re-hash ile tüm key'ler yeni diziye taşınır. (Bu O(n))
Seyrek olduğu durumlarda amortize O(1) kabul edilir, çünkü re-hash nadiren gerçekleştiğinde, uzun vadede işlem başına düşen ortalama maliyet düşük kalır. Ancak çok sık re-hash yapılırsa bu avantajı kaybederiz ve performans düşebilir.
Şimdi hash-based yapı üzerinde epeyce konuştuğumuza göre, bunun bir kullanım alanını yani veritabanlarında hash join mekanizmasını ele alarak tüm bu avantajları nasıl kullandığını gözlemleyebiliriz.
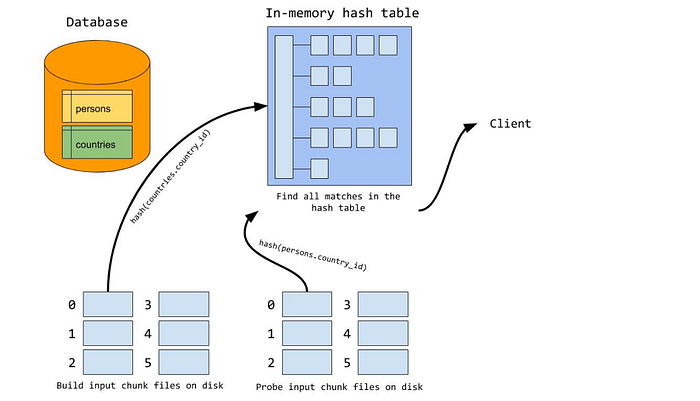
Veritabanı join işlemlerinde, küçük tabloyu bir hash table (örneğin bir Dictionary) olarak belleğe yüklemek (build), ardından büyük tabloyu satır satır işleyerek (probe) join anahtarlarını eşleştirmek, işlemi büyük ölçüde hızlandırır.
Burada örnek bir senaryo üzerinden bunun daha net anlaşılmasını sağlamaya çalışırsak :
Veritabanımızda iki tablo var:
"persons" tablosu: Kişilerin bilgilerini içeriyor. Her kişinin bağlı olduğu bir ülke var (country_id sütunu).
"countries" tablosu: Ülkelerin bilgilerini içeriyor. Her ülkenin bir country_id'si var.
Amacımız, "persons" tablosundaki her kişinin ülke bilgilerini bulmak için "countries" tablosu ile bir JOIN işlemi yapmak.
Hash Join Adımları
-Build Aşaması (Küçük Tablo Belleğe Yükleniyor)
"countries" tablosu nispeten küçük olduğu için (örneğin 200 ülke), belleğe yüklenebilir.
Her satır için (country_id, country_name) çiftleri bir hash table'a eklenir.
Hash fonksiyonu: hash(countries.country_id)
Sonuç olarak, country_id → country_name eşleşmesi bellekte hazır hale gelir.
-Probe Aşaması (Büyük Tablo Tarama ve Eşleşme Kontrolü)
"persons" tablosu büyük (milyonlarca kayıt) olduğundan, belleğe yüklemek mümkün değil.
Her satır işlenirken, kişinin country_id değeri hash fonksiyonuna sokulur ve hash table'da karşılığı olup olmadığı kontrol edilir.
Eğer eşleşme varsa, kişi bilgisiyle ülke bilgisi birleştirilir.
Hash fonksiyonu: hash(persons.country_id)
Ortalama O(1) sürede erişim sağlanır, yani kişi tablosundaki her satır için hızlı bir lookup yapılır.
Şu ana kadar array-based ve hash-based veri yapılarının nasıl çalıştığını detaylıca inceledik. Veri yapılarının organizasyonu ve performans üzerindeki etkilerini ele aldık. Özellikle, hash table'ların veriye hızlı erişimi nasıl sağladığını, load factor, re-hash ve hash join gibi kavramları analiz ettik.
Ancak, şimdiye kadar hep bellek içinde verimli veri erişimi ve işlem hızını konuştuk. Peki bu noktada veri tek bir makineye sığmayacak kadar büyükse ne olur?
Böyle durumlarda veritabanları ve büyük ölçekli sistemler tek bir sunucuda değil, birden fazla sunucuya bölünerek çalıştırılır. Bunun için kullanılan temel tekniklerden biri sharding'dir.
Sharding, büyük bir veri kümesini birden fazla sunucuya dağıtarak yatay ölçeklendirme sağlar. Hashing prensipleri, sharding mekanizmasında da merkezi bir rol oynar çünkü hangi verinin hangi sunucuya gideceğini belirlemek için genellikle hash fonksiyonları kullanılır.
Dağıtık Sistemlere Geçiş: Sharding
Sharding (parçalama) yaparak, veriyi birden çok makineye (node'a) dağıtırız. Ancak tam da bu noktada Key'in hangi node'a gideceği başlı başına büyük bir problem haline gelir.
Basit mod Yaklaşımı ya da hash mod N :
Bu basit ancak büyük ölçekli sistemlerde sorunlara yol açabilecek bir yaklaşımdır.
shardIndex = hash(key) mod NBurada N = sharding node sayısı.
Örneğin 4 node varsa mod 4, 8 node varsa mod 8.
Ancak N değişince (yeni node ekleme/çıkarma) mod N±1 tüm dağıtımı değiştirir. Verinin neredeyse tamamı yer değiştirmek zorunda kalır (reshard). Bu durum büyük ölçekli sistemlerde ciddi bir performans ve operasyonel maliyet yaratır. Bu sorunu aşmak için, hash mod N yaklaşımına kıyasla çok daha esnek ve ölçeklenebilir bir çözüm olan Hash Ring yaklaşımı kullanılabilir.
Consistent Hashing: Hash Ring Consistent hashing, "hash ring" kavramıyla ekleme/çıkarma anında minimum veri taşınmasını sağlar.
Hash Ring, veri ve sunucuları bir halka üzerinde konumlandırarak sharding sürecini daha verimli hale getirir. Böylece, yeni bir sunucu eklemek veya çıkarmak gerektiğinde, sadece belirli bir veri aralığı taşınır ve tüm dağılım değişmez.
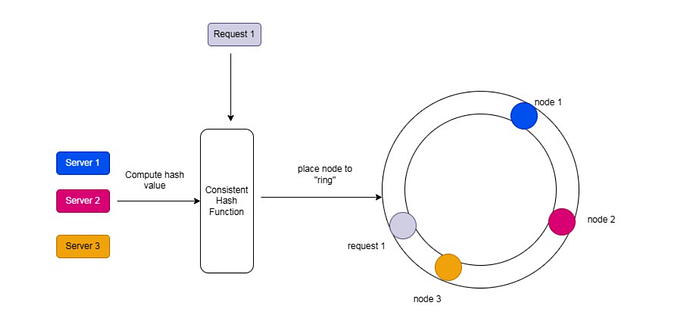
Şimdi bu görsel üzerinden açıklayarak daha da netleştirelim.
Request 1 (İstek) Hash Hesaplanıyor:
Bir istemciden gelen istek (Request 1), bir hash fonksiyonundan geçirilerek belirli bir değer üretiliyor.
Örneğin: hash(request1) → 1900
Sunucular (Nodes) Halka Üzerinde Konumlandırılmış:
Her sunucu da kendi hash değeri ile belirli bir noktaya atanmış.
Hash Ring Üzerinde Veri Yönlendirme:
Request 1'in hash değeri hesaplandıktan sonra halkada kendisine en yakın olan (saat yönünde) sunucuya yönlendirilir.
Bu durumda, Request 1 en yakın olan Node 3'e gidecektir.
Yine bu görsel üzerinden aslında hash ring'in çalışma mantığını daha prensiplere dökerek açıklayalım :
1. Dairesel Yapı
0'dan büyük bir sayıya (örneğin 0–359 derece) kadar olan aralık bir çember olarak düşünelim.
2. Sunucuların Konumlandırılması
Her sunucu, kendi hash değeriyle çember üzerinde bir konuma yerleştirilir.
Node 1: 30°
Node 2: 150°
Node 3: 270°
3. Verilerin Yerleştirilmesi
Her veri anahtarı (key), aynı hash fonksiyonu ile çember üzerinde bir konuma atanır.
Örneğin, bir request'in hash değeri 90° ise, saat yönünde ilerleyerek ilk karşılaşılan sunucuya (Node 2, 150°) atanır.
4. Sunucu Ekleme/Çıkarma
Yeni bir node eklendiğinde, sadece ilgili "komşu aralık"taki veriler yeni node'a taşınır.
Örnek:
Eğer Node 4 (90°) konumuna eklenirse, 30°–90° aralığındaki veriler artık Node 4'e gidecek.
90°–150° arasındaki veriler ise yine Node 2'de kalacak.
Böylece tüm veri seti yeniden dağıtılmaz yalnızca 30°–90° arasındaki veriler taşınmış olur.
Cassandra, DynamoDB, Memcached gibi büyük ölçekli veri yönetim sistemleri, Hash Ring modelini kullanarak sürdürülebilir, verimli ve ölçeklenebilir mimariler oluşturuyorlar.
Tüm bu uzun uzadıya anlattıklarımı özetleyecek olursam,
İlk olarak dinamik array (List) yapılarının, contiguous memory sayesinde rastgele erişimi O(1) sağladığını ancak ekleme/silme gibi işlemlerde capacity yönetiminin O(n) maliyeti getirdiğini inceledik. Ardından hash-based (Dictionary/Hash Table) yapıların, key–value eşleşmelerinde hash function kullanarak ortalama O(1) performans sunduğunu, collision durumlarında ise separate chaining yöntemiyle (genellikle linked list) bu sorunu nasıl çözdüğünü inceledik.
Bu temel prensiplerden sonra, verinin tek bir makineye sığmadığı durumlarda sharding ile veriyi parçalara ayırmanın ve basit "mod N" stratejisinin node eklemede oluşturduğu problemleri daha sonra hash ring ile minimal veri taşıma yoluyla nasıl çözdüğümüzü de ele aldık.
Eğer yazının bu kısmına kadar okumuşsanız, çok teşekkür ederim.
Benimle LinkedIn üzerinden iletişime geçebilirsiniz.
KAYNAKÇA
1. GeeksforGeeks. (n.d.). Sharding vs. Consistent Hashing. Retrieved from https://www.geeksforgeeks.org/sharding-vs-consistent-hashing/
2. GeeksforGeeks. (n.d.). Consistent Hashing. Retrieved from https://www.geeksforgeeks.org/consistent-hashing/
3. GeeksforGeeks. (n.d.). Separate Chaining Collision Handling Technique in Hashing. Retrieved from https://www.geeksforgeeks.org/separate-chaining-collision-handling-technique-in-hashing/
4. GeeksforGeeks. (n.d.). Applications of Linked List Data Structure. Retrieved from https://www.geeksforgeeks.org/applications-of-linked-list-data-structure/
5. GeeksforGeeks. (n.d.). Hash Table Data Structure. Retrieved from https://www.geeksforgeeks.org/hash-table-data-structure/
6. MySQL. (n.d.). Hash Join in MySQL 8. Retrieved from https://dev.mysql.com/blog-archive/hash-join-in-mysql-8/
7. Databricks. (n.d.). Hash Buckets. Retrieved from https://www.databricks.com/glossary/hash-buckets
8. Farokhi, A. (n.d.). Array vs. List: Compare Array and List Performance in C#. Retrieved from https://alirezafarokhi.medium.com/array-vs-list-compare-array-and-list-performance-in-c-722316603c8c
9. GeeksforGeeks. (n.d.). Difference Between Contiguous and Noncontiguous Memory Allocation. Retrieved from https://www.geeksforgeeks.org/difference-between-contiguous-and-noncontiguous-memory-allocation/