

Recommendation Systems have become the part an parcel of everyone's life. Be it Netflix, YouTube or Amazon we encounter such systems in our daily life. But How do these recommender systems work? The answer is not simple, though the answer is pretty common. All of these companies, end up using pretty much very similar tech stack to solve this particular problem. In this article I will try to explain how Ranking and Recommendations work for these large scale systems.
From a very high point this stack looks like:
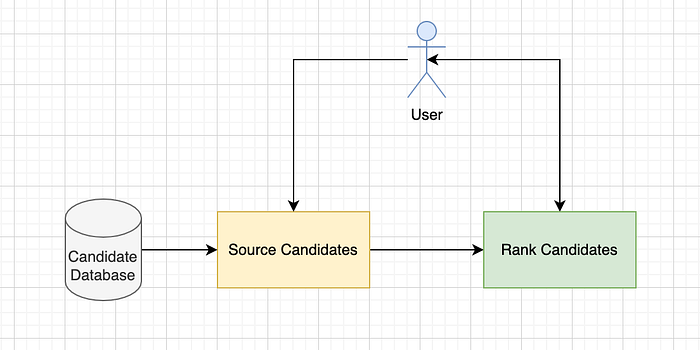
So, when a user hits the system, we source(get) candidate items for this particular user and then rank those items based on the preference for this particular user. And hence the term "relevance ranking". The items can be anything. For Netflix, its the movies and TV series. For Amazon it is the products. And so on. What is more interesting is how you build logic to get/source these items, and how you build the logic to rank them to the end user.
So, What are these L1 and L2 Rankers I keep hearing about?
In industry terms, the Sourcing logic to get the list of products to rank is known as the L1 ranker while the ranking logic is called the L2 ranker. Why 2 rankers? Because the work of each of the ranker is different and each one optimizes for different criterion. For instance the L1 ranker optimizes for recall while the L2 ranker optimizes for precision.And it makes sense as well. The L1 ranker optimizes for recall as in it tries to find out the best products that might be clicked/bought by the user if they are shown to the user. While the L2 ranker tries to rank those products based on precision so that the user sees the most relevant product first and takes action on it.
Retrieval: The L1 Ranker
Before coming up with a solution for retrieval, lets try to think about the problems that we face at sourcing time.
- Can we score all of the items in real time when a user comes to the system? This would mean running a model over all the products. That means scoring lets say 1M products each time we recieve a request. Too much computation heavy! And just forget about the latency of such a system.
- Can we store recommendations for all the users in our system and all the products in our system using a batch job? Assuming a 1M userbase and 1M product base of a system, such a index (or whatever system you create for storing these recommendations) would be prohibitively (1Mx1M) large. And 1 M was a very conservative estimate. Companies like Google, Amazon now have user bases in Billions.
So, how do we solve this problem? Should we use some rule-based system? Or is there something better that we can do? The most common solution for this problem is to use embeddings and Two Tower Sparse Networks.
What TTSNs?
TTSN or two-tower Sparse networks are based on a very simple idea. Can we get the user and item based embeddings if we have user and item based features and interactions? These embeddings then, can help us in fast retrieval. A very simple architecture for a TTSN looks like:
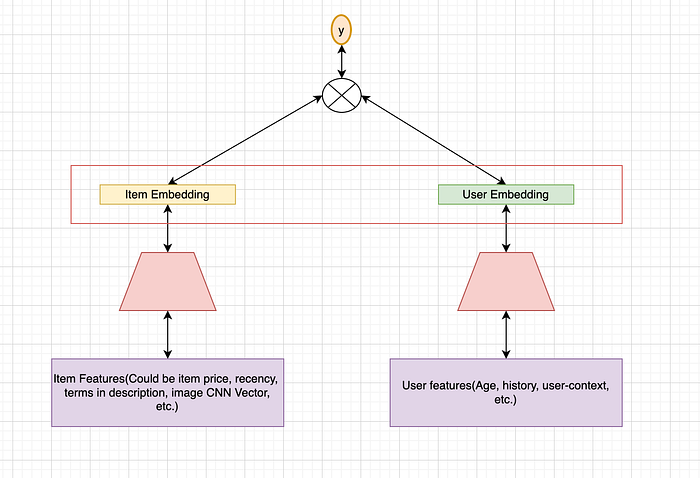
Training Data: The training data for these generally consists of implicit feedback (Based on logs of user and item interaction) from the user for an item. For example if Adam has seen the movie "Shawshank Redemption" the pair of Item-User pair (Adam, "Shawshank Redemption") would be a positive training example. What about the negative training example? A negative training example could be (Adam, any Random movie from our 1M Dataset that Adam has not watched based on implicit feedback). For example: (Adam, "Borat") as Adam has never watched "Borat"
Architecture: For each example, we will have (Item features), and (user features). Continuing the previous example, for Adam we will have their age, previous interactions with system, most liked genre and so on. And for the movie "Shawshank Redemption" we will have its description, genre, poster image CNN vector, and a lot of other features. Both of these features will be fed into two separate towers in the network. The task of each encoder(which can just be a series of dense layers) is to take the input features and spit out a k-dimensional(normally 128 or 64) vector which can be thought of as an embedding for items and users. These embeddings vectors then are multiplied using the dot-product operator to arrive at a single score which is the final output of the system.
Loss Function: The loss function to use normally depends on the label of implicit feedback, but as most of the time this problem is framed as a binary (0/1) problem, the most common loss function used to optimize this network is the binary cross-entropy loss.
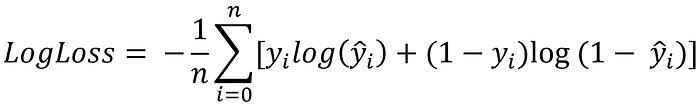
What is the output? Once we have trained these TTSN networks using our training data, the next step is to just run these networks on all our 1M users and all our 1M items. The results are then stored in some Embedding Index for fast retrieval. One key point to understand here is that once this TTSN is trained, we really can get any product embedding irrespective of the user and any user embedding irrespective of the product. We just need to know the user/product features.
A very important note about these embeddings: These embeddings for user and items are created by minimizing the loss obtained on the dot product of the user and item embeddings. This means that if a user likes a particular movie they will be pretty close in the embedding space.
And, what happens at prediction time?
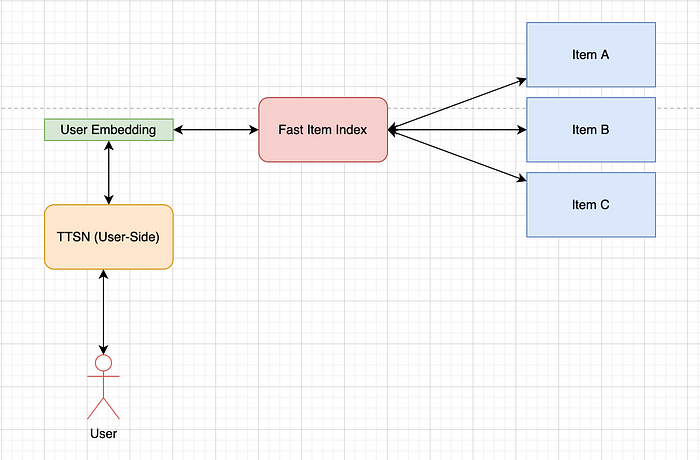
Now, we come to the idea of Embedding Index. Imagine if we just had a system/index that could find out the top most similar k embeddings to a given embedding lightning fast. Then whenever we will have a new user in our system, we can find its embedding(using one side of the TTSN) and use that embedding to find out similar movies to that user using our imaginary index that contains embeddings for movies.
And such systems are there aplenty. The most common of these are FAISS, SAISS, NMS, etc.
Ranking: The L2 Ranker
Once the retrieval is done, we have the L2 Ranker in place. This is the place where we use complex Deep Learning models, GBTs and other complex models to rank the items in the order that would be most relevant to the users of the system. The idea behind such a ranker is optimize a cost function which might be based on user preferences as well as the business objective. This ranker is particularly based on the following 3 sets of features:
- Item Features: Item Price, Item category etc.
- User Features: Demographic features, premium subscriber etc.
- Item-User Interaction Features: User Interactions with Category of item, etc.
Once we have these features in rows we can train any neural network or a ML model to predict P(Click) or P(Buy) given the features from our training data. We can use these probability values to then rank the items in the best possible way.
Continue Learning
If you want to learn more about Recommendation Systems, I would like to call out an excellent course on Unsupervised Learning, Recommenders, and Reinforcement Learning on Coursera from DeepLearning.AI. Do check it out.
I am going to be writing more beginner-friendly posts in the future too. Follow me up at Medium or Subscribe to my blog to be informed about them. As always, I welcome feedback and constructive criticism and can be reached on Twitter @mlwhiz.
Also, a small disclaimer — There might be some affiliate links in this post to relevant resources, as sharing knowledge is never a bad idea.