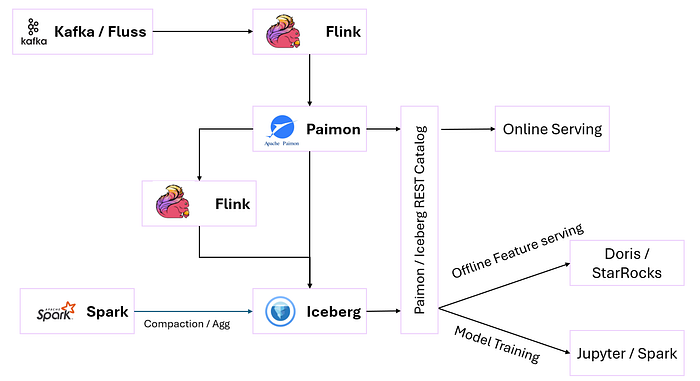

A feature platform is a critical component for machine learning (ML) systems, enabling feature registration, online feature serving, offline feature serving, and a feature store to manage and serve feature data efficiently. Using the real-time lakehouse stack of Apache Flink, Apache Paimon, Apache Iceberg, and high-performance query engines like Apache Doris, StarRocks, or Presto, we can build a robust feature platform that supports both real-time and batch ML workloads.
Features of this setup:
- Streaming-native with batch fallback
- Unified compute path, multiple materializations
- Fresh, fast features online with deep, consistent history offline
- Zero vendor lock-in and high flexibility
Components
- Feature Registration — A system to define, version, and manage feature definitions.
- Feature Store — A centralized repository to store and manage feature data, supporting both online and offline use cases.
- Online Feature Serving — Low-latency feature retrieval for real-time ML inference (e.g., recommendation systems).
- Offline Feature Serving — High-throughput feature retrieval for training ML models or batch inference.
Feature Registration (Central Registry)
- Metadata about features (name, data type, freshness, owner, tags, lineage)
- Tracks what features are materialized where (Paimon, Iceberg, etc.)
- Can be built using: (DB + REST API)
- Or integrate with Feast, or open-source alternatives like Tecton SDK + metadata DB
A centralized Feature repository to store and manage feature data, supporting both online and offline use cases.
Online Feature Store (Paimon)
Why Paimon? Paimon supports streaming writes and low-latency reads, making it ideal for online feature serving. It handles incremental updates and changelog-based processing, perfect for real-time feature updates
- Write feature vectors as Flink changelogs
- Can integrate with Flink SQL or Table API
Supports:
- Primary-key-based upserts
- Time-versioned lookups
- Low-latency serving via key-based retrieval
Offline Feature Store (Iceberg)
Why Iceberg? Iceberg's ACID transactions, schema evolution, and partitioning make it ideal for large-scale, historical feature data used in model training.
Store snapshots of features for:
- Model training
- Batch scoring
- Backfills & re-computation
Supports
- Time-travel (for training/inference consistency)
- Schema evolution
- Large-scale batch analytics
- Flink or Spark aggregates Paimon data (e.g., daily or hourly aggregates) and writes to Iceberg.
- Iceberg tables are partitioned by date or user_id for efficient querying.
Online Feature Serving
For online feature serving, low-latency access is critical. Paimon serves as the primary store, with Fluss as an optional in-memory layer for ultra-low-latency use cases (e.g., <10ms).
Paimon for Online Serving
- Paimon tables store precomputed features (e.g., user_click_rate, last_purchase_amount).
- Flink continuously updates Paimon tables with fresh data from event streams.
- A serving layer (e.g., a REST API or gRPC service) queries Paimon for features using key-value lookups.
Redis for Ultra-Low Latency (Optional)
- For ultra-low-latency use cases, Redis can cache hot features in memory.
- Flink writes to Redis for ephemeral features with a TTL, which are then flushed to Paimon for persistence.
- Example: A bidding system retrieves user_bid_score from Redis
Implementation:
- Deploy a Flink job to compute and update features in Paimon (or Fluss).
- Use a lightweight API server (e.g., FastAPI, gRPC) to serve features from Paimon/Fluss to ML models.
Fast Offline Serving: Doris / ClickHouse / Presto
- Query feature tables via external table connectors (Iceberg/Paimon)
- Vectorized OLAP for: Batch inference, Monitoring dashboards, Training set exploration
Materialization Paths
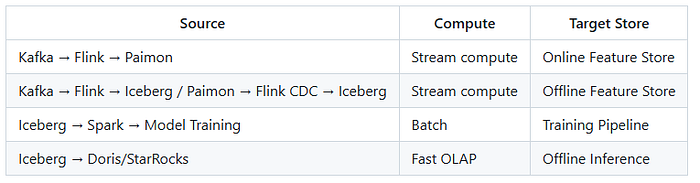
Feature Consistency Strategy

Optional Enhancements
- Feature Lineage UI → Show data flows and freshness across stores
- Feature Testing Framework → Alert on drift/null spikes/value range anomalies
- Monitoring Dashboard → Doris/StarRocks over Iceberg for model observability