


Introduction
By 2026, the world will rely on data more than ever before. With the explosion of IoT devices, connected applications, and AI-driven analytics, the global datasphere is projected to exceed 200 zettabytes. Every click, sensor reading, and transaction contributes to a digital universe that's growing faster than traditional data systems can handle.
In this new era, data engineering stands at the center of digital transformation. The demand is no longer just for scalable pipelines, it's for self-managing, intelligent data ecosystems that can process, reason, and act autonomously.
This is where Artificial Intelligence (AI) steps in. From automating ETL processes to governing data in real time, AI is redefining the way data engineering operates. In this final chapter of our AI in Data Engineering series, we'll explore how AI is powering the shift toward autonomous data infrastructure, outline a step-by-step guide to building next-generation pipelines, and share key insights for 2026 and beyond.

Step 1: Understanding the AI-Driven Data Engineering Landscape
AI has evolved from being a toolkit to becoming the core operating system of modern data engineering.
Today, machine learning and intelligent orchestration enable:
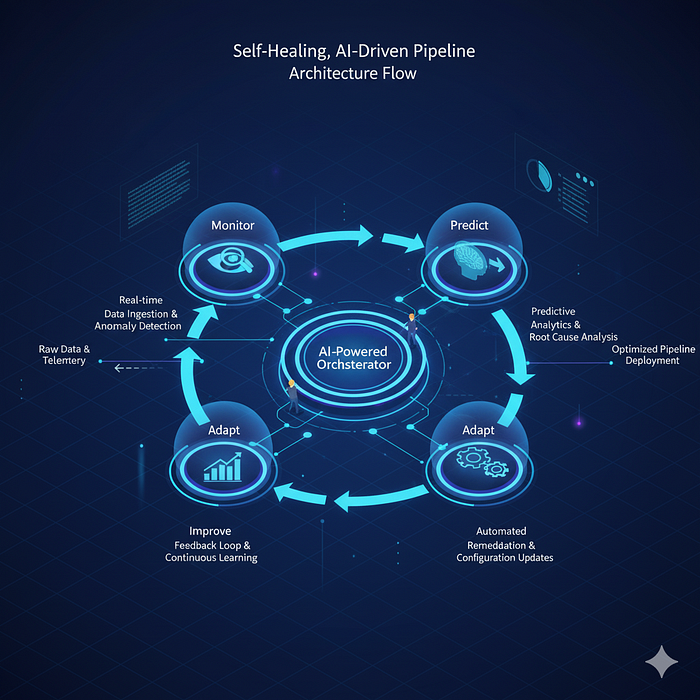
- Self-healing pipelines that predict and prevent failures before they occur.
- AI-optimized workflows that adjust resource allocation automatically.
- Real-time governance that detects policy breaches instantly.
- LLM-powered discovery that turns natural language into structured queries.
This convergence of AI and data engineering is creating autonomous data systems, pipelines that learn from patterns, adapt to change, and continuously optimize without manual intervention.
Step 2: Incorporating AI into Data Pipelines
Integrating AI begins with identifying where automation and intelligence create the most impact.
High-value integration points include:
- Data Ingestion: Use AI to identify and prioritize the most relevant data sources dynamically.
- Data Cleansing: Implement ML models to detect anomalies, missing values, or schema drift automatically.
- Data Transformation: Use AI-powered query optimization (e.g., Snowflake Cortex, dbt-AI) to generate or refine SQL logic.
- Data Delivery: Automate routing of transformed data to downstream systems based on predictive usage patterns.
Frameworks like Airflow, Kafka, and Snowflake now support embedded AI features, making it easier for engineers to weave intelligence into existing architectures.

Step 3: Using AI for Data Quality, Observability, and Governance
As pipelines scale, data quality and trust become critical. In 2026, successful data teams will rely on AI-augmented observability to monitor every layer of their ecosystem.
- AI for Quality: Models trained on historical datasets can detect outliers, missing data, or sudden metric shifts in real time.
- AI for Observability: Agents continuously track lineage, freshness, and performance, alerting teams to anomalies before they cascade downstream.
- AI for Governance: NLP models classify sensitive data, enforce access policies, and automatically log compliance actions.
This intelligent oversight transforms governance from a compliance checkbox into a living, adaptive system that ensures both security and reliability at scale.
Step 4: Building AI-Enabled Data Warehouses and Lakes
Modern warehouses like Snowflake, Databricks, and BigQuery are evolving into AI-first platforms, where machine learning is built directly into storage and compute layers.
Key trends shaping the AI-augmented warehouse of 2026 include:
- Automated Indexing & Compression: AI determines the most efficient storage formats dynamically.
- Query Optimization: LLMs rewrite queries on the fly for maximum performance.
- Metadata Intelligence: AI auto-documents datasets and recommends joins or transformations.
- Federated Learning: Models learn collaboratively across datasets without exposing sensitive information.
This synergy between AI and cloud infrastructure allows pipelines to operate at the speed of insight, not the speed of manual configuration.
Step 5: The Rise of AI Agents in Data Engineering
Looking ahead, the next evolution of data engineering will be AI agents that collaborate across the stack.
Imagine a world where:
- A Data Quality Agent monitors all ingestion flows, correcting errors autonomously.
- A Query Optimization Agent rewrites inefficient SQL in real time.
- A Governance Agent flags compliance risks before auditors do.
- A Knowledge Agent summarizes daily pipeline health and performance in plain English.
These agents, powered by LLMs and multi-agent frameworks will enable self-orchestrating, self-auditing, and self-improving data systems, marking the dawn of the autonomous data era.
Tips and Best Practices for 2026
- Adopt a "Human-in-the-Loop" Mindset AI can manage systems, but humans define ethics, priorities, and context. Keep oversight at the core.
- Invest in Continuous Learning Data engineering is now an AI-driven discipline. Mastering MLOps, prompt engineering, and data observability tools is essential.
- Start with Pilot Pipelines Automate one process, like anomaly detection or SQL generation, before scaling across your ecosystem.
- Leverage Platform Integrations Use cloud-native AI capabilities from Snowflake Cortex, Databricks Mosaic AI, or GCP Vertex AI to accelerate adoption.
- Prioritize Explainability and Trust As pipelines grow more autonomous, transparency in AI decision-making becomes mission-critical.
Conclusion
As we enter 2026, data engineering is no longer just a technical discipline, it's the backbone of intelligent enterprise operations. AI has moved from enhancing workflows to governing and optimizing them autonomously, ushering in a new era of AI-augmented, self-evolving data ecosystems.
For data engineers, the message is clear: the future belongs to those who blend technical expertise with intelligent automation. Whether it's through LLM-powered pipelines, predictive maintenance, or AI-driven governance, the next generation of data systems will be autonomous, adaptive, and deeply collaborative between humans and machines.