


To test the quality of any classification system like Support Vector Machines, there's need to perform some evaluation metrics. Support Vector Machines are classification algorithm which I explained briefly in kernels.
A Little Background
Precision and Recall are both extensively used in Information Extraction. Precision is the number of document retrieved that are relevant and Recall is the number of relevant document that are retrieved.
Relevance is how useful the information presented is to the topic being discussed at the moment.
Let's look at an example of a conversation between John and Josh:
If John said "I love ice cream" and Josh replied with "I have a friend named John Doe", then what Josh just said is in no way relevant to what John was implying but if Josh had said "I have a friend named John Doe who also loves ice cream", then Josh's statement becomes relevant because it now relates to John's statement.
Precision and Recall are both extremely useful in understanding what set of documents or information was presented and how many of those documents are actually useful to the question being asked.
Although Precision and Recall are sometimes confused as synonyms of each other, they are not.
Precision and Recall are inversely proportional to each other and thus understanding their differences is important in building an efficient classification system.
Let's consider another example:
Let's say I searched on Google for "what is precision and recall?" and in less than a minute I have about 15,600,000 results.
Let's say out of these 15.6 million results, the relevant links to my question were about 2 million. Assuming there were also about 6 million more results that were relevant but weren't returned by Google, for such system we would say that it has a precision of 2M/15.6M and a recall of 2M/8M.
This implies that the probability of Google's algorithm to retrieve all the relevant links was 0.25 (recall) and the probability that all the retrieved links were relevant is 0.13 (precision).
Another way to think of precision and recall is this:
If someone asked you to list the names of 5 presents you got last Christmas but you couldn't exactly remember the 5 names — so you randomly guessed seven times. Out of the 7 names you remembered, 5 was recalled correctly while 2 were gifts you received on your birthday. Even though you got a 100% recall (5/5) your precision was 71.4% (5/7).
Now that I have gotten your feet wet on Precision and Recall, let's dive a little bit deeper.
Type I & II Errors
To talk about Precision and Recall without mentioning Type I & II errors is like narrating the history of Muhammad Ali and skipping "Boxing" — me
Type I Error
This is the incorrect rejection of a true Null Hypothesis (Ho).
Null Hypothesis is a statement that is by default true unless proven otherwise.
Type I Error leads to False Positive (FP). For instance, when a document is returned as "relevant" from a search engine and it turns out to be "irrelevant".
An example is a fire alarm going off when in fact there is no fire. This kind of error is synonymous to "believing a lie" or "a false alarm".
Type II Error
This is the incorrect retaining of a false Null Hypothesis (Ho).
This is synonymous to when the system ignore the possibility that it might not have retrieved some document which are relevant.
This type of error leads to False Negative (FN). That is, not retrieving the relevant documents that should have been retrieved.
An example of this is a fire breaking out and the fire alarm does not ring. This kind of error is synonymous to "failing to believe a truth" or "a miss".
Consider the table below:
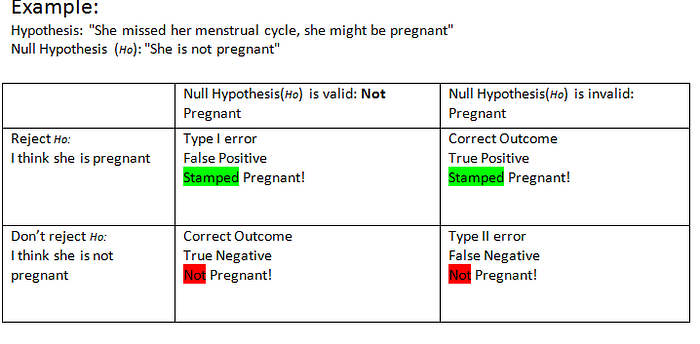
False Positives and False Negatives are the two unique characteristics of Precision and Recall respectively.

To decrease one means increasing the other as
P α 1/R
Some Mathematical Formulae
In a classification task,
Precision P = TP/(TP+ FP)i.e {number of True Positive (correctly retrieved documents)}/{(Total number of document retrieved)}
Recall R = TP/(TP + FN)i.e {number of True Positive (correctly retrieved documents)}/{(Total number of relevant document retrieved)}
From the Google search example, a perfect Precision score of 1.0 would mean every result retrieved by the search engine was relevant (but says nothing about whether all the relevant document was retrieved)
Whereas a perfect Recall score of 1.0 means all relevant document were retrieved from the search engine (but says nothing about how many of the result retrieved was irrelevant).
This is not a question of one or the other as the decision made on one automatically affects the other. Therefore, for every system, there is a usually a benchmark which is considered as "acceptable" without losing too many features.
For any system to be able to achieve maximum Precision (no false positive) and maximum Recall (no false negative) there needs to be an absence of type I and II errors.
Precision and Recall scores are not discussed in isolation. Instead, either values for one measure are compared for a fixed level at the other measure (e.g. precision at a recall level of 0.75) or both are combined into a single measure.
Examples for measures that are a combination of Precision and Recall are the F-measure
F = 2 * ((Precision * Recall)/(Precision + Recall))This measure usually referred to as F1 score, it is the average of Precision and Recall when they are close. This is the harmonic mean.
Other relevant metrics are Accuracy, Confusion matrix and Contingency table.
Go ahead and explore!
Thanks to Pelumi and Hamza for reading the draft.
Relevant Links