

Regression analysis can be described as a statistical technique used to predict/forecast values of a dependent variable (response) given values of one or more independent variables (predictors or features). Regression is considered a form of supervised machine learning; this is an algorithm that builds a mathematical model to determine a relationship between inputs and desired outputs. There are numerous regression models that can be generated, so let's cover regression mathematics first and then jump into three common models.
Regression Mathematics
Before we look at any code, we should understand a little about the math behind a regression model. As mentioned, regression models can have multiple input variables, or features, but for this article, we will use a single feature for simplicity. Regression analysis involves making a guess at what type of function would fit your dataset the best, whether that be a line, an nth degree polynomial, a logarithmic function, etc. Regression models assume the dataset follows this form:

Here, x and y are our feature and response at observation i, and e is an error term. The goal of the regression model is to estimate the function, f, so that it most closely fits the dataset (neglecting the error term). The function, f, is the guess we make about what type of function would best fit our dataset. This will become more clear as we get to the examples. To estimate the function, we need to estimate the β coefficients. The most common method is ordinary least squares, which minimizes the sum of squared errors between our dataset and our function, f.

Minimizing the squared errors will result in an estimate of our β coefficients, labeled as β-hat. The estimate can be obtained using the normal equations that result from the ordinary least squares method:
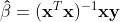
In turn, we can use these estimated β coefficients to create an estimate for our response variable, y.

The y-hat value here is the predicted, or forecasted, values for an observation, i. The prediction is generated by using our estimated β coefficients and a feature value, x.
To determine how well our regression model performs, we can calculate the R-squared coefficient. This coefficient evaluates the scatter of the dataset around the regression model prediction. In other words, this is how well the regression model fits the original dataset. Typically, the closer the value is to 1.0, the better the fit.
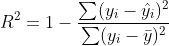
To properly evaluate your regression model, you should compare R-squared values for multiple models (the function, f) before settling on which to use for forecasting future values. Let's start coding to better understand the concepts of regression models.
Importing Libraries
For these examples, we will need the following libraries and packages:
- NumPy is used to create numerical arrays (defined as np for ease of calling)
- random from NumPy is used to create noise in a function to simulate a real-world dataset
- pyplot from matplotlib is used to display our data and trendlines
# Importing Libraries and Packages
import numpy as np
from numpy import random
import matplotlib.pyplot as pltCreating and Displaying Test Dataset
To create the dataset, we can create an x array that will be our feature and a y array that will be our response. The y array is an arbitrary exponential function. Using the random package, we will introduce noise into our data to simulate some kind of real-world data.
# Creating Data
x = np.linspace(0, 4, 500) # n = 500 observations
random.seed(10) # For consistent results run-to-run
noise = np.random.normal(0, 1, x.shape)
y = 0.25 * np.exp(x) + noise
# Displaying Data
fig = plt.figure()
plt.scatter(x, y, s=3)
plt.title("Test Data")
plt.xlabel("x")
plt.ylabel("y")
plt.show()Here is the dataset that we apply regression analysis to:
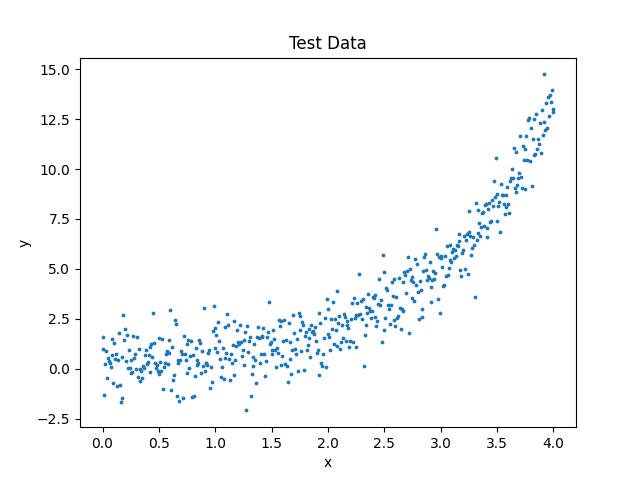
Let's take a second to look at this plot. We know that an exponential equation was used to create this data, but if we did not know that information (which you wouldn't if you are performing regression analysis), we might look at this data and think a 2nd degree polynomial would fit the dataset the best. However, as best practice, you should evaluate a couple different models to see which performs the best. Then, you will use the best model to create your predictions. Now let's look at a couple regression models separately and see how their results compare.
Linear Regression
As mentioned in the mathematics section, for regression analysis you guess a model, or function. For a linear model, the following form is taken for our function, f:
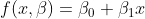
The next step is creating the matrices for the normal equations (in the mathematics section) that estimate our β coefficients. They should look like the following:
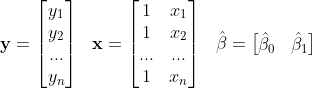
Using our dataset, our estimated β coefficients and therefore linear regression model will be:
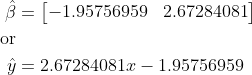
# Linear Regression
X = np.array([np.ones(x.shape), x]).T
X = np.reshape(X, [500, 2])
# Normal Equation: Beta coefficient estimate
b = np.linalg.inv(X.T @ X) @ X.T @ np.array(y)
print(b)
# Predicted y values and R-squared
y_pred = b[0] + b[1] * x
r2 = 1 - sum((y - y_pred) ** 2)/sum((y - np.mean(y)) ** 2)
# Displaying Data
fig = plt.figure()
plt.scatter(x, y, s=3)
plt.plot(x, y_pred, c='red')
plt.title("Linear Model (R$^2$ = " + str(r2) + ")")
plt.xlabel("x")
plt.ylabel("y")
plt.legend(["Data", "Predicted"])
plt.show()The resulting regression model is shown below:
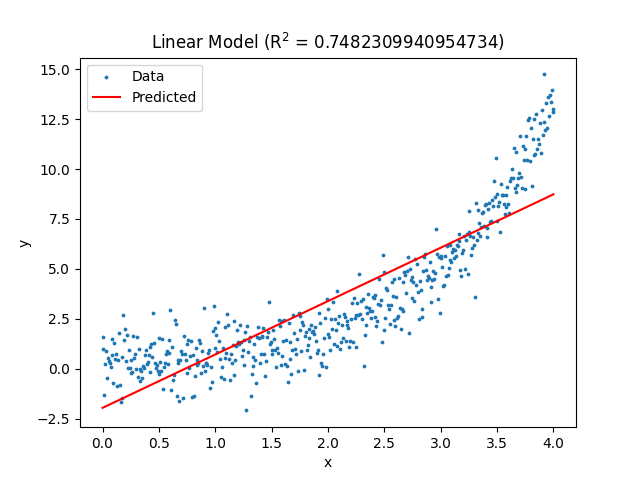
As you can see in the title of the plot, the linear regression model has an R-squared value of about 0.75. This means the linear model fits the data okay, but if we were to collect more data, we would likely see the value of R-squared decrease substantially.
Polynomial Regression
The general form of polynomial regression is as follows:
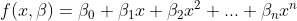
This article shows the form of the function, f, as a second order polynomial. You can add more polynomial terms in a similar fashion to fit your needs; however, be wary of overfitting.
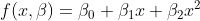
Creating the matrices for the normal equations gives the following:
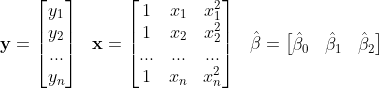
Using these matrices, the estimated β coefficients and polynomial regression model will be:
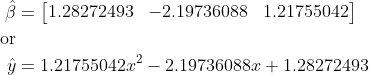
# Polynomial Regression
X = np.array([np.ones(x.shape), x, x ** 2]).T
X = np.reshape(X, [500, 3])
# Normal Equation: Beta coefficient estimate
b = np.linalg.inv(X.T @ X) @ X.T @ np.array(y)
print(b)
# Predicted y values and R-squared
y_pred = b[0] + b[1] * x + b[2] * x ** 2
r2 = 1 - sum((y - y_pred) ** 2)/sum((y - np.mean(y)) ** 2)
# Displaying Data
fig = plt.figure()
plt.scatter(x, y, s=3)
plt.plot(x, y_pred, c='red')
plt.title("2$^{nd}$ Degree Poly. Model (R$^2$ = " + str(r2) + ")")
plt.xlabel("x")
plt.ylabel("y")
plt.legend(["Data", "Predicted"])
plt.show()The resulting plot:
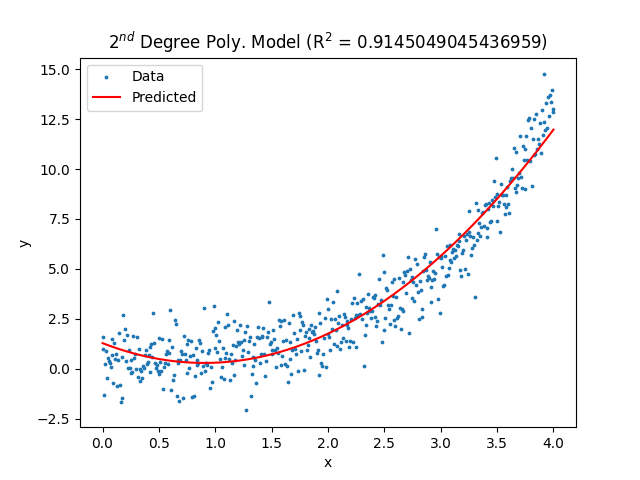
Notice the 2nd degree polynomial does a much better job of matching the dataset and achieves an R-squared value of about 0.91. However, if we look towards the end of the dataset, we notice the model is underpredicting those data points. This should encourage us to look into other models.
Exponential Regression
If we decided against the polynomial model, our next choice could be an exponential model of the form:
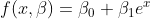
Again, creating the matrices for the normal equations gives the following:
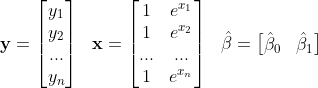
Now, with the estimated β coefficients, the regression model will be:
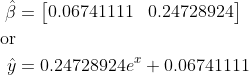
Note that the leading coefficient on the exponential term closely matches the simulated data leading coefficient.
# Exponential Regression
X = np.array([np.ones(x.shape), np.exp(x)]).T
X = np.reshape(X, [500, 2])
# Normal Equation: Beta coefficient estimate
b = np.linalg.inv(X.T @ X) @ X.T @ np.array(y)
print(b)
# Predicted y values and R-squared
y_pred = b[0] + b[1]*np.exp(x)
r2 = 1 - sum((y - y_pred) ** 2)/sum((y - np.mean(y)) ** 2)
# Displaying Data
fig = plt.figure()
plt.scatter(x, y, s=3)
plt.plot(x, y_pred, c='red')
plt.title("Exponential Model (R$^2$ = " + str(r2) + ")")
plt.xlabel("x")
plt.ylabel("y")
plt.legend(["Data", "Predicted"])
plt.show()The resulting figure:
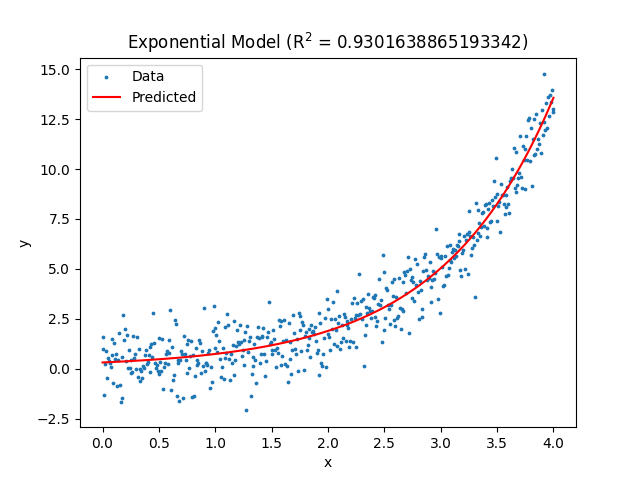
Notice there is improvement in the R-squared value compared to the 2nd degree polynomial model. Even more promising is the end of the dataset fits this model better than the 2nd degree polynomial. Given that information, we should use the exponential model to predict future y values for the most accurate result possible.
That wraps up the article. Hopefully this gives you an idea of how regression analysis can be performed in Python and how to use it properly for real-world scenarios. If you learned something, give me a follow and check out my other articles on space, mathematics, and Python! Thank you!