
Project recap
The goal of the project and this series of articles is to walk the path of AI-based product creation, from the first baby steps to, progressively, building a more complex solution. Each stage of the journey will build on the previous one:
- In the first article of the series, we created a PoC to validate our approach, using NLP.
- In the second article of the series, we will build an app using streamlit as the front end, and fastAPI in the backend.
- In the third article, we migrated the data to an ElasticSearch database.
- In this last article, we will create a telegram bot to ask for suggestions.
It's time for the MvP to talk!
Motivation
In previous articles, we created a user interface using streamlit to power our user interactions. Although this is a fantastic tool for prototyping and quickly iterating to test new features, it was difficult to use on mobile devices, and some of the searching options (using an ISBN, for instance) required keeping the references in memory, slowing the app and affecting user experience.
After considering different options, we decided to pursue an interaction that we called "Ask your bookseller", where we would try to emulate the interaction between customer and bookseller, using a Telegram bot.
The reason for choosing Telegram over other options is that it is almost ubiquitous in today's handheld devices and features several implementation features making it almost seamless to integrate with our stack in Python.
The bot
Bear in mind that this is an MvP and any added complexity beforehand, might result in work that needs to be refined or rejected altogether in the next stage. To keep the efforts at a minimum, our bot, Llum, is going to be quite simple.
She will receive a message from the user containing what they want to read about, and return a list of suggestions so that the user can pick from. As you can remember from the first article, we used a multilingual model, which means that Llum will be able to speak in more than 25 different languages!
Setting up the bot
The first step is to create the bot using the Telegram API. There are hundreds of tutorials over the internet, or you can go directly to their site to set it up and obtain your token.
Then, we need to decide how the bot is going to listen to incoming messages. As this is still in an MvP phase, we decided to use polling (checking every T seconds if there are new messages or not) as it was easier to set up, but if you are experienced creating bots, WebHooks are definitely the best option, albeit at a higher entry cost.
When our bot receives a message from a user, it will encode the message into the embedding, find their closest matches by similarity in the ElasticSearch database that we built on the third article and return the information of the suggestions via Telegram. So let's modify the docker-compose stack accordingly.
Updating the stack
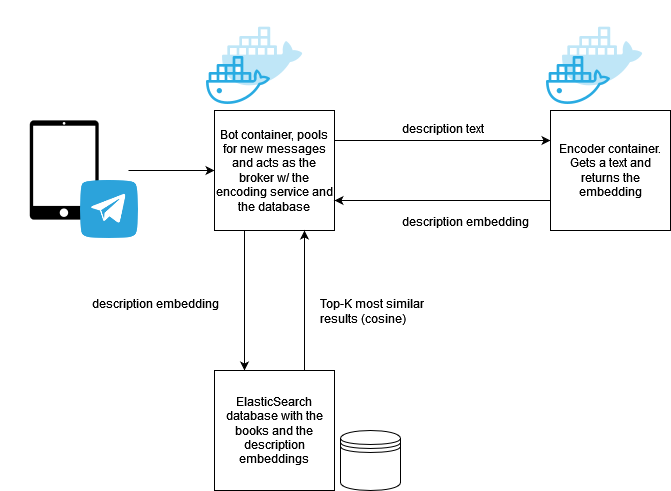
The final stack for this MvP is composed by 3 different containers: the ElasticSearch database from the previous article, the bot container, that acts as the broker for the rest of the microservices, and the encoding service that transforms any text it receives, in this case, the descriptions of the books, in their respective embeddings.
One could argue that the structure could be further simplified by integrating the embedding model in the bot container, but this will constraint future flexibility for the bot (webhooks, polling strategies, etc.) as well as require more resources for the NLP model. In this case, it is better to decouple both, as each one has a different goal.
Dockerfile
You can find below the gist of the Dockerfile. The app code, as always, can be found in my github repository.
Testing
To wrap up the series and this MvP, let's ask Llum for recommendations in three different languages: English, French and Spanish, and see how she performs.
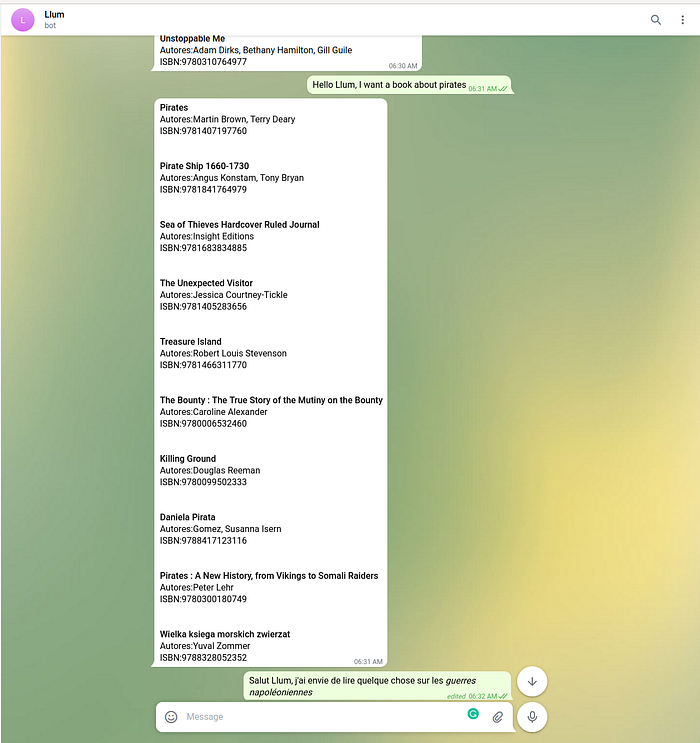
The results are not bad at all. Although pirates is an easy term to find, Llum was able to retrieve context-related results, like the third entry, or Treasure Island.

In this case, we get mixed results. A good set of context-related results (Waterloo) but entries like the last two, do not make a lot of sense. For this reason, if we iterate over the MvP, we might incorporate other filters, like the category, to exclude some results that are near from an embeddings standpoint.
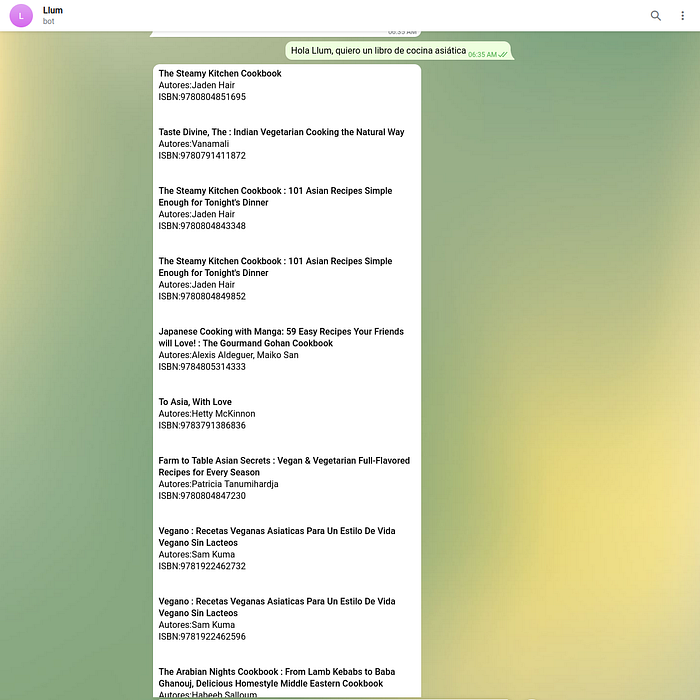
Our last test was asking for Asian cooking books, in Spanish. We got a good set of results, in different languages (mainly Spanish and English) and from diverse Asian cooking traditions, which is great!
Wrapping up and next steps
Throughout this series of articles, we have created an MvP that gives book recommendations based on what the user wants to read.
"Backstage", there is a multilingual NLP model powering the search engine, and an ElasticSearch database to retrieve the candidates efficiently.
The idea evolved from a proof of concept, where the user persona was the bookseller (using ISBNs to retrieve candidates, proposing suggestions based on a book title), to an MvP where it was the final reader. This meant changing our front-end from a web application build with Python and streamlit, to a Telegram BOT our users could directly talk to, Llum.