

Introduction
The ability to process extensive context has become a critical capability in modern AI applications. While cloud-based LLMs like Claude and GPT-4 offer large context windows, the costs can be prohibitive for production workloads processing millions of tokens daily. Enter local deployment: I recently achieved a 1 million token context window running NVIDIA's Nemotron-3-Nano (30B parameters) on a single RTX 3090 using vLLM, opening up new possibilities for cost-effective, privacy-preserving AI applications.
In this post, I'll walk through the deployment process, performance characteristics, and demonstrate a real-world multi-agent workflow that leverages this massive context capability: automated legacy codebase modernization.
Why Nemotron-3-Nano?
NVIDIA's Nemotron-3-Nano is part of the Nemotron family, specifically designed for efficiency, extended context processing, and agentic AI workflows. This is not just another large language model — it's a hybrid architecture that combines the best of multiple approaches.
Model Architecture
NVIDIA Nemotron-3-Nano-30B-A3B:
- Total Parameters: 31.6 billion
- Active Parameters: ~3.6B per token (including embeddings)
- Activation Rate: Only ~11% of parameters active per forward pass
- Context Window: Up to 1 million tokens
Hybrid Architecture Components
52 Total Layers:
- 23 Mamba-2 Layers — Efficient sequential processing and long-context handling
- 23 MoE (Mixture-of-Experts) Layers — Each with 128 routed experts + 1 shared expert
- 6 experts activated per token (sparse activation)
- Learned MLP router for expert selection
3. 6 Transformer Layers — Grouped Query Attention (GQA) with 2 groups for high-accuracy reasoning
Why This Architecture Matters
Efficiency Through Sparsity:
- Activating only 3.6B out of 31.6B parameters per token delivers:
- 3.3x higher throughput than dense 30B models (Qwen3–30B)
- Comparable accuracy to much larger dense models
- Fits in consumer GPU VRAM despite large total parameter count
Hybrid Design Benefits:
- Mamba-2: Handles long sequences efficiently, low-latency state space model
- MoE: Specialized expertise routing for different domains (math, code, reasoning)
- Transformers: Precision attention for complex reasoning tasks
Quantization Options:
- FP8: Native NVIDIA quantization, ~99% accuracy retention vs BF16
- BF16: Full precision for maximum quality
- GGUF (Q4_K_M, Q6, Q8): Community quantizations for different hardware
Hardware Requirements
My Setup (Single GPU)
- GPU: NVIDIA RTX 3090 (24GB VRAM)
- RAM: 64GB system RAM
- Storage: NVMe SSD (for fast model loading)
- CUDA: 12.1+
Recommended Configurations
Single RTX 3090 (24GB VRAM)
Perfect for the FP8 variant with 1M context. This is the minimum recommended setup for running Nemotron-3-Nano FP8 with full context capability.
Capabilities:
- FP8 model: ✅ Full 1M context
- BF16 model: ❌ Requires 60GB+ VRAM
- Expected speed: 15–20 tokens/sec
- VRAM usage: 21–23GB (tight but stable)
Dual RTX 3090 with NVLink (48GB Combined VRAM) — RECOMMENDED
Significant upgrade enabling both better performance and higher quality options.
Capabilities:
- FP8 model: ✅ Full 1M context with 2x throughput
- BF16 model: ✅ Full precision for maximum quality!
- Expected speed: 25–35 tokens/sec (FP8), 20–25 tokens/sec (BF16)
- VRAM usage per GPU: 10–12GB (FP8), 20–22GB (BF16)
- Concurrent requests: 8–16 vs 4 on single GPU
Multi-GPU Launch Command:
python -m vllm.entrypoints.openai.api_server \
--model nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8 \
--dtype float16 \
--tensor-parallel-size 2 \
--max-model-len 1048576 \
--gpu-memory-utilization 0.95 \
--host 0.0.0.0 \
--port 8000 \
--trust-remote-code \
--enable-prefix-caching \
--max-num-batched-tokens 16384 \
--max-num-seqs 8Other GPU Options
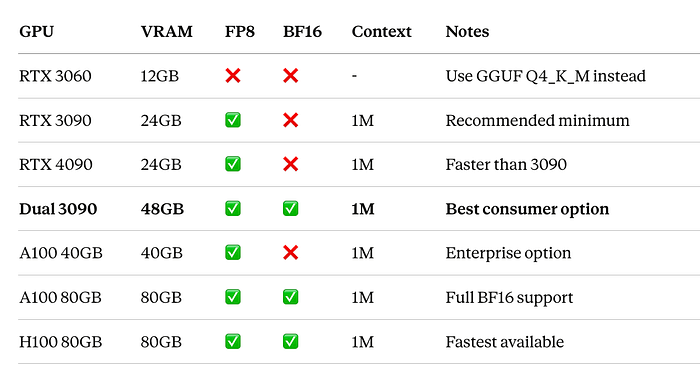
Why RTX 3090 (or Dual 3090)?
Single RTX 3090:
- 24GB VRAM is the minimum for FP8 with 1M context
- 384-bit memory bus provides excellent bandwidth
- Ampere architecture has native FP8 support
- Available on used market for ~$800–1,200
- Best price/performance for local LLM deployment
Dual RTX 3090 with NVLink:
- 48GB combined enables BF16 full precision
- NVLink (600 GB/s) enables efficient tensor parallelism
- 2x-3x better throughput than single GPU
- Can run maximum quality while single GPU cannot
- Still cheaper than single A100 (~$2,400 vs $10,000+)
- ROI in 3–4 weeks vs cloud costs
Deployment with vLLM
vLLM (Very Large Language Model) is a high-performance inference engine that dramatically improves throughput and memory efficiency through techniques like PagedAttention and continuous batching.
Installation
# Create conda environment
conda create -n vllm python=3.10
conda activate vllm
# Install vLLM with CUDA support
pip install vllm
# Install HuggingFace tools for model download
pip install huggingface_hub hf_transfer
# Optional: Install accelerate for faster loading
pip install accelerateDownloading the Model from HuggingFace
NVIDIA provides several ready-to-use versions on HuggingFace that work directly with vLLM. Each variant is optimized for different hardware configurations and use cases.
Available Versions:

Which Version Should You Choose?
- RTX 3090 (24GB): Use FP8 — optimal balance of quality and memory efficiency
- RTX 4090 (24GB): Use FP8 — faster inference with same quality
- A100/H100 (40GB+): Use BF16 for maximum accuracy
- Fine-tuning: Use Base model as starting point
Method 1: Using HuggingFace CLI (Recommended)
# Install HuggingFace Hub with transfer acceleration
pip install huggingface_hub hf_transfer
# Enable fast downloads (5-10x faster)
export HF_HUB_ENABLE_HF_TRANSFER=1
# Download FP8 version (recommended for RTX 3090)
huggingface-cli download nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8 \
--local-dir ./nemotron-fp8 \
--local-dir-use-symlinks False
# Download BF16 version (for high-end GPUs)
huggingface-cli download nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16 \
--local-dir ./nemotron-bf16 \
--local-dir-use-symlinks FalseMethod 2: Using Python Script
# download_model.py
import os
from huggingface_hub import snapshot_download
# Enable fast transfer (5-10x faster downloads)
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1"
# Download the FP8 quantized model
model_path = snapshot_download(
repo_id="nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8",
local_dir="./nemotron-fp8",
local_dir_use_symlinks=False,
resume_download=True # Resume if interrupted
)
print(f"✅ Model downloaded to: {model_path}")Why FP8 for RTX 3090?
- Memory Efficient: Fits comfortably in 24GB VRAM with room for large context
- Quality Preservation: <2% accuracy loss vs BF16 on most benchmarks
- Native Support: Optimized for NVIDIA Ada/Ampere architectures
- Faster Inference: 1.5–2x faster than BF16 on consumer GPUs
- Cost Effective: Get production performance on affordable hardware
Download Time Estimates:
- With
hf_transfer: 15-25 minutes (FP8), 30-45 minutes (BF16) - Without
hf_transfer: 45-90 minutes (FP8), 90-180 minutes (BF16)
Launching vLLM Server
Single GPU Deployment
# launch_vllm.py
from vllm import LLM, SamplingParams
import argparse
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--model-path", default="./nemotron-fp8",
help="Path to downloaded model")
parser.add_argument("--port", type=int, default=8000)
args = parser.parse_args()
# Configuration for 1M context with FP8 on single GPU
llm = LLM(
model=args.model_path,
tensor_parallel_size=1, # Single GPU
max_model_len=1048576, # 1M tokens
gpu_memory_utilization=0.95, # Use 95% of VRAM
trust_remote_code=True,
dtype="float16", # Data type for computation
quantization=None, # FP8 is already quantized
max_num_batched_tokens=8192,
max_num_seqs=4,
enable_prefix_caching=True, # Cache common prefixes
)
print(f"✅ Model loaded successfully!")
print(f"Context window: {llm.llm_engine.model_config.max_model_len:,} tokens")
print(f"GPU Memory: {llm.llm_engine.model_config.gpu_memory_utilization*100}%")
return llm
if __name__ == "__main__":
main()Start OpenAI-Compatible API Server (Single GPU):
# Using vLLM's built-in server
python -m vllm.entrypoints.openai.api_server \
--model ./nemotron-fp8 \
--dtype float16 \
--max-model-len 1048576 \
--gpu-memory-utilization 0.95 \
--host 0.0.0.0 \
--port 8000 \
--trust-remote-code \
--enable-prefix-cachingMulti-GPU Deployment (Dual RTX 3090 with NVLink)
If you have dual RTX 3090s with NVLink, you can leverage tensor parallelism for significantly better performance:
Check NVLink Status:
# Verify NVLink is active
nvidia-smi nvlink --status
# Expected output:
# GPU 0: NVIDIA GeForce RTX 3090
# Link 0: Active
# Link 1: ActiveLaunch with Tensor Parallelism (FP8):
python -m vllm.entrypoints.openai.api_server \
--model ./nemotron-fp8 \
--dtype float16 \
--tensor-parallel-size 2 \
--max-model-len 1048576 \
--gpu-memory-utilization 0.95 \
--host 0.0.0.0 \
--port 8000 \
--trust-remote-code \
--enable-prefix-caching \
--max-num-batched-tokens 16384 \
--max-num-seqs 8Launch with BF16 Full Precision (Dual GPU Only):
With 48GB combined VRAM, you can run the full BF16 model for maximum quality:
# Download BF16 model
huggingface-cli download nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16 \
--local-dir ./nemotron-bf16 \
--local-dir-use-symlinks False
# Launch with tensor parallelism
python -m vllm.entrypoints.openai.api_server \
--model ./nemotron-bf16 \
--dtype bfloat16 \
--tensor-parallel-size 2 \
--max-model-len 1048576 \
--gpu-memory-utilization 0.90 \
--host 0.0.0.0 \
--port 8000 \
--trust-remote-code \
--enable-prefix-caching \
--max-num-batched-tokens 8192 \
--max-num-seqs 4Multi-GPU Performance Benefits:
Verify Server is Running:
# Test the API
curl http://localhost:8000/v1/models
# Sample completion
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "./nemotron-fp8",
"prompt": "Explain quantum computing in simple terms:",
"max_tokens": 100,
"temperature": 0.7
}'Performance Characteristics
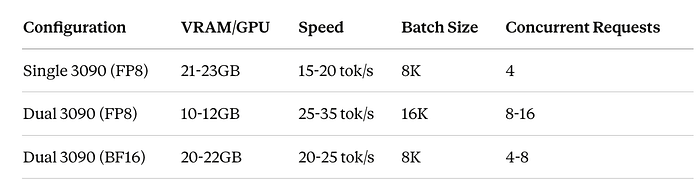
Single RTX 3090 (FP8)
With this setup, I achieved:
- Context Window: 1,048,576 tokens (1M)
- Throughput: ~15–20 tokens/second for generation
- Latency: ~2–3 seconds for first token (with large context)
- Memory Usage: ~22GB VRAM with full context
- Batch Size: 4–8 concurrent sequences
- Cost: $0 per token (versus $3–10 per million tokens on cloud)
Dual RTX 3090 with NVLink (FP8)
With tensor parallelism across two GPUs:
- Context Window: 1,048,576 tokens (1M)
- Throughput: ~25–35 tokens/second for generation
- Latency: ~1.5–2 seconds for first token
- Memory Usage: ~10–12GB VRAM per GPU
- Batch Size: 8–16 concurrent sequences
- Throughput Improvement: 2x-3x over single GPU
- Cost: $0 per token
Dual RTX 3090 with NVLink (BF16 — Maximum Quality)
Running full precision for best quality:
- Context Window: 1,048,576 tokens (1M)
- Throughput: ~20–25 tokens/second for generation
- Latency: ~2–2.5 seconds for first token
- Memory Usage: ~20–22GB VRAM per GPU
- Quality: Maximum (no quantization loss)
- Batch Size: 4–8 concurrent sequences
- Cost: $0 per token
Use Case: Multi-Agent Legacy Code Modernization
Large context windows enable powerful multi-agent workflows that were previously impractical. Let's explore a real-world scenario: automated modernization of a legacy enterprise codebase.
The Challenge
Imagine modernizing a 15-year-old legacy code base with:
- 500+ source files (Java, JSP, SQL)
- 300,000+ lines of code
- Complex interdependencies
- Outdated patterns and security vulnerabilities
- Minimal documentation
Traditional approaches require months of manual analysis. With our 1M context setup, we can process the entire codebase simultaneously.
Multi-Agent Architecture
Our workflow uses four specialized agents:
- Analyzer Agent: Maps code structure and dependencies
- Security Agent: Identifies vulnerabilities and outdated patterns
- Modernization Agent: Proposes refactoring strategies
- Validator Agent: Ensures changes maintain functionality
Implementation
# multi_agent_modernization.py
import asyncio
import json
from typing import List, Dict
from openai import AsyncOpenAI
class LegacyCodeModernizer:
"""Multi-agent system for legacy code modernization"""
def __init__(self, vllm_base_url="http://localhost:8000/v1"):
self.client = AsyncOpenAI(
base_url=vllm_base_url,
api_key="dummy" # vLLM doesn't need real API key
)
self.model = "nvidia/nemotron-3-nano-30b-instruct"
async def load_codebase(self, directory: str) -> str:
"""Load entire codebase into context"""
codebase = []
file_count = 0
for root, dirs, files in os.walk(directory):
# Skip common non-code directories
dirs[:] = [d for d in dirs if d not in [
'node_modules', '.git', 'build', 'dist', 'target'
]]
for file in files:
if file.endswith(('.java', '.jsp', '.sql', '.xml', '.properties')):
filepath = os.path.join(root, file)
try:
with open(filepath, 'r', encoding='utf-8') as f:
content = f.read()
codebase.append(f"\n{'='*80}\n")
codebase.append(f"FILE: {filepath}\n")
codebase.append(f"{'='*80}\n")
codebase.append(content)
file_count += 1
except Exception as e:
print(f"Error reading {filepath}: {e}")
full_codebase = "".join(codebase)
token_estimate = len(full_codebase) // 4 # Rough estimate
print(f"Loaded {file_count} files (~{token_estimate:,} tokens)")
return full_codebase
async def analyzer_agent(self, codebase: str) -> Dict:
"""Agent 1: Analyze code structure and dependencies"""
prompt = f"""You are a senior software architect analyzing a legacy codebase.
CODEBASE:
{codebase}
Perform a comprehensive analysis:
1. **Architecture Overview**
- Identify architectural patterns (MVC, layered, etc.)
- Map major components and their responsibilities
- Note coupling between components
2. **Dependency Graph**
- Identify critical dependencies between modules
- Find circular dependencies
- Map external library dependencies
3. **Code Metrics**
- Average file size and complexity
- Code duplication patterns
- Test coverage (if tests exist)
4. **Technology Stack**
- Languages and frameworks used
- Database technologies
- Build and deployment tools
Provide a structured JSON analysis."""
response = await self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": prompt}],
temperature=0.3,
max_tokens=4096
)
analysis_text = response.choices[0].message.content
print(f"\n{'='*80}\nANALYZER AGENT COMPLETED\n{'='*80}\n")
return {"analysis": analysis_text, "raw_codebase": codebase}
async def security_agent(self, codebase: str, analysis: Dict) -> Dict:
"""Agent 2: Identify security vulnerabilities and outdated patterns"""
prompt = f"""You are a security expert reviewing legacy code.
CODEBASE ANALYSIS:
{analysis['analysis']}
FULL CODEBASE:
{codebase}
Identify security and quality issues:
1. **Security Vulnerabilities**
- SQL injection risks
- XSS vulnerabilities
- Authentication/authorization weaknesses
- Hardcoded credentials or secrets
- Insecure cryptography
2. **Outdated Patterns**
- Deprecated APIs and libraries
- Anti-patterns (God objects, tight coupling, etc.)
- Performance bottlenecks
- Concurrency issues
3. **Compliance Issues**
- GDPR/privacy concerns
- PCI-DSS violations (if handling payments)
- Logging and audit trail gaps
Prioritize issues by severity (Critical, High, Medium, Low).
Provide specific file locations and code snippets."""
response = await self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": prompt}],
temperature=0.3,
max_tokens=4096
)
security_report = response.choices[0].message.content
print(f"\n{'='*80}\nSECURITY AGENT COMPLETED\n{'='*80}\n")
return {"security_findings": security_report}
async def modernization_agent(
self,
codebase: str,
analysis: Dict,
security: Dict
) -> Dict:
"""Agent 3: Propose modernization strategy"""
prompt = f"""You are a modernization consultant creating a transformation roadmap.
ARCHITECTURE ANALYSIS:
{analysis['analysis']}
SECURITY FINDINGS:
{security['security_findings']}
CODEBASE:
{codebase}
Create a comprehensive modernization plan:
1. **Quick Wins** (1-2 months)
- Critical security fixes
- Update vulnerable dependencies
- Add basic test coverage
2. **Medium-term Improvements** (3-6 months)
- Refactor high-coupling modules
- Introduce design patterns
- Modernize UI framework
- Implement API layer
3. **Long-term Transformation** (6-12 months)
- Microservices migration (if appropriate)
- Cloud-native refactoring
- Implement CI/CD
- Complete test automation
For each phase:
- Specific tasks with effort estimates
- Risk assessment
- Dependencies and prerequisites
- Expected business value
Include concrete code examples for key refactorings."""
response = await self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": prompt}],
temperature=0.4,
max_tokens=6144
)
modernization_plan = response.choices[0].message.content
print(f"\n{'='*80}\nMODERNIZATION AGENT COMPLETED\n{'='*80}\n")
return {"modernization_plan": modernization_plan}
async def validator_agent(
self,
codebase: str,
analysis: Dict,
security: Dict,
modernization: Dict
) -> Dict:
"""Agent 4: Validate proposed changes"""
prompt = f"""You are a quality assurance architect validating a modernization plan.
ORIGINAL CODEBASE:
{codebase[:50000]}... [truncated for validation]
PROPOSED MODERNIZATION:
{modernization['modernization_plan']}
Validate the plan:
1. **Risk Assessment**
- Identify high-risk changes
- Potential breaking changes
- Data migration concerns
- Rollback strategies
2. **Testing Strategy**
- Required test coverage for each phase
- Integration test scenarios
- Performance test requirements
- User acceptance criteria
3. **Compatibility Analysis**
- Backward compatibility concerns
- API contract changes
- Database schema impacts
- Third-party integration effects
4. **Recommendations**
- Suggest pilot areas for new patterns
- Recommend phased rollout approach
- Identify necessary training
- Propose metrics for success
Provide actionable validation report."""
response = await self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": prompt}],
temperature=0.3,
max_tokens=4096
)
validation_report = response.choices[0].message.content
print(f"\n{'='*80}\nVALIDATOR AGENT COMPLETED\n{'='*80}\n")
return {"validation_report": validation_report}
async def run_modernization_workflow(self, codebase_dir: str) -> Dict:
"""Execute complete multi-agent workflow"""
print("🚀 Starting Legacy Code Modernization Workflow")
print("="*80)
# Step 1: Load codebase
print("\n📁 Loading codebase...")
codebase = await self.load_codebase(codebase_dir)
# Step 2: Run agents sequentially (each builds on previous)
print("\n🔍 Running Analyzer Agent...")
analysis = await self.analyzer_agent(codebase)
print("\n🔒 Running Security Agent...")
security = await self.security_agent(codebase, analysis)
print("\n⚡ Running Modernization Agent...")
modernization = await self.modernization_agent(
codebase, analysis, security
)
print("\n✅ Running Validator Agent...")
validation = await self.validator_agent(
codebase, analysis, security, modernization
)
# Compile final report
final_report = {
"architecture_analysis": analysis['analysis'],
"security_findings": security['security_findings'],
"modernization_plan": modernization['modernization_plan'],
"validation_report": validation['validation_report'],
"metadata": {
"codebase_size": len(codebase),
"estimated_tokens": len(codebase) // 4,
"files_analyzed": codebase.count("FILE:"),
"timestamp": datetime.now().isoformat()
}
}
return final_report
# Example usage
async def main():
modernizer = LegacyCodeModernizer()
# Point to your legacy codebase
codebase_directory = "/path/to/legacy/src"
# Run workflow
report = await modernizer.run_modernization_workflow(codebase_directory)
# Save comprehensive report
with open("modernization_report.json", "w") as f:
json.dump(report, f, indent=2)
print("\n" + "="*80)
print("✅ Modernization analysis complete!")
print("📄 Report saved to: modernization_report.json")
print("="*80)
if __name__ == "__main__":
import os
from datetime import datetime
asyncio.run(main())Sample Output
Here's what the multi-agent analysis produces for a typical legacy system:
{
"architecture_analysis": {
"pattern": "Layered monolith with MVC influences",
"components": {
"presentation": "JSP pages with embedded business logic",
"business": "Java servlets and service classes",
"data": "Direct JDBC with hand-written SQL",
"integration": "SOAP web services for external systems"
},
"critical_dependencies": [
"Oracle JDBC 11g (outdated)",
"Apache Struts 1.3 (EOL)",
"Spring Framework 2.5 (very old)"
],
"coupling_issues": [
"Direct database access from presentation layer",
"Business logic scattered across JSPs",
"No clear service boundaries"
]
},
"security_findings": {
"critical": [
{
"type": "SQL Injection",
"location": "BookingServlet.java:145",
"code": "SELECT * FROM bookings WHERE id = " + request.getParameter('id')",
"recommendation": "Use PreparedStatement with parameterized queries"
},
{
"type": "Hardcoded Credentials",
"location": "DatabaseConfig.java:23",
"code": "password = \"admin123\"",
"recommendation": "Move to secure credential vault"
}
],
"high": [
{
"type": "Outdated Cryptography",
"location": "PasswordUtil.java:56",
"code": "Using MD5 for password hashing",
"recommendation": "Migrate to bcrypt or Argon2"
}
]
},
"modernization_plan": {
"phase_1_quick_wins": {
"duration": "6-8 weeks",
"tasks": [
{
"task": "Fix SQL injection vulnerabilities",
"effort": "2 weeks",
"priority": "Critical",
"example": "Convert to JPA/Hibernate with named queries"
},
{
"task": "Update vulnerable dependencies",
"effort": "1 week",
"priority": "High",
"details": "Upgrade Spring to 6.x, migrate from Struts"
}
]
},
"phase_2_refactoring": {
"duration": "12-16 weeks",
"tasks": [
{
"task": "Introduce service layer",
"effort": "4 weeks",
"pattern": "Extract business logic from JSPs into service classes"
},
{
"task": "Implement REST API",
"effort": "6 weeks",
"technology": "Spring Boot with OpenAPI"
}
]
}
}
}Why This Workflow Needs Large Context
This multi-agent modernization workflow fundamentally requires large context for several reasons:
1. Complete Codebase Awareness
Each agent needs to see the entire codebase simultaneously to:
- Understand cross-file dependencies
- Identify patterns spanning multiple modules
- Avoid suggesting changes that break distant components
- Maintain consistency across recommendations
2. Agent Chaining with Full Context
Later agents build on earlier work while still accessing raw code:
- Modernization agent references both analysis AND codebase
- Validator cross-references all previous outputs
- No information loss between agent handoffs
3. Holistic Analysis
Legacy systems have emergent properties not visible in isolated files:
- Circular dependencies across modules
- Implicit coupling through shared state
- Architecture patterns only visible system-wide
4. Accuracy of Recommendations
With full context, agents can:
- Suggest refactorings that truly improve structure
- Avoid introducing new bugs or vulnerabilities
- Prioritize based on actual system impact
- Provide file-specific, line-specific guidance
Token Economics: A 300K line codebase might consume 400K-600K tokens. Processing this through all four agents with cloud LLMs:
- Claude Opus: ~$18–27 per complete workflow
- GPT-4 Turbo: ~$24–36 per workflow
- Local Nemotron: $0 (after hardware investment)
For ongoing development with daily analyses, local deployment becomes dramatically more cost-effective.
Multi-GPU Deployment Guide
If you have dual RTX 3090s with NVLink, you can significantly improve performance and unlock additional capabilities.
Why Multi-GPU Matters
Benefits of Dual RTX 3090:
- 48GB Combined VRAM — Run BF16 full precision (impossible on single GPU)
- 2x-3x Throughput — Larger batch sizes and more concurrent requests
- Better Stability — Plenty of headroom for 1M context window
- Faster Inference — NVLink (600 GB/s) enables efficient tensor parallelism
- Cost Effective — Still cheaper than single A100 ($2,400 vs $10,000+)
Tensor Parallelism Explained
Tensor Parallelism (TP) splits the model layers across multiple GPUs. With NVLink, GPUs communicate efficiently during forward passes:
Single GPU:
┌─────────────────────────┐
│ GPU 0 (24GB) │
│ Full Model (31.6B) │
│ ~22GB used │
└─────────────────────────┘
Dual GPU with TP=2:
┌─────────────────────────┐ ┌─────────────────────────┐
│ GPU 0 (24GB) │ │ GPU 1 (24GB) │
│ Half Model (~15.8B) │←→│ Half Model (~15.8B) │
│ ~10-12GB used │ │ ~10-12GB used │
└─────────────────────────┘ └─────────────────────────┘
NVLink (600 GB/s)Setup and Verification
1. Verify NVLink Connection:
# Check NVLink status
nvidia-smi nvlink --status
# Expected output:
# GPU 0: NVIDIA GeForce RTX 3090
# Link 0: Active
# Link 1: Active
# GPU 1: NVIDIA GeForce RTX 3090
# Link 0: Active
# Link 1: Active
# Check topology
nvidia-smi topo -m
# Expected: GPU0 <-> GPU1 should show NV2 (NVLink Gen 2)2. Launch Configuration Script:
# launch_dual_gpu.py
import subprocess
import sys
def check_nvlink():
"""Verify NVLink is working"""
result = subprocess.run(['nvidia-smi', 'nvlink', '--status'],
capture_output=True, text=True)
if 'Active' in result.stdout:
active_count = result.stdout.count('Active')
print(f"✅ NVLink is active ({active_count} links detected)")
return True
else:
print("⚠️ NVLink not detected - will use slower PCIe")
print(" Performance will be degraded")
return False
def launch_fp8_dual_gpu():
"""Launch FP8 with tensor parallelism for maximum throughput"""
cmd = """
python -m vllm.entrypoints.openai.api_server \\
--model ./nemotron-fp8 \\
--dtype float16 \\
--tensor-parallel-size 2 \\
--max-model-len 1048576 \\
--gpu-memory-utilization 0.95 \\
--host 0.0.0.0 \\
--port 8000 \\
--trust-remote-code \\
--enable-prefix-caching \\
--max-num-batched-tokens 16384 \\
--max-num-seqs 8
"""
print("\n" + "="*80)
print("Launching FP8 on Dual RTX 3090 (Maximum Throughput)")
print("="*80)
print("\nExpected Performance:")
print(" - Speed: 25-35 tokens/sec")
print(" - VRAM per GPU: 10-12GB")
print(" - Concurrent requests: 8-16")
print(" - Context: Full 1M tokens")
print("="*80 + "\n")
subprocess.run(cmd, shell=True)
def launch_bf16_dual_gpu():
"""Launch BF16 for maximum quality"""
cmd = """
python -m vllm.entrypoints.openai.api_server \\
--model ./nemotron-bf16 \\
--dtype bfloat16 \\
--tensor-parallel-size 2 \\
--max-model-len 1048576 \\
--gpu-memory-utilization 0.90 \\
--host 0.0.0.0 \\
--port 8000 \\
--trust-remote-code \\
--enable-prefix-caching \\
--max-num-batched-tokens 8192 \\
--max-num-seqs 4
"""
print("\n" + "="*80)
print("Launching BF16 on Dual RTX 3090 (Maximum Quality)")
print("="*80)
print("\nExpected Performance:")
print(" - Speed: 20-25 tokens/sec")
print(" - VRAM per GPU: 20-22GB")
print(" - Concurrent requests: 4-8")
print(" - Context: Full 1M tokens")
print(" - Quality: Maximum (no quantization)")
print("="*80 + "\n")
subprocess.run(cmd, shell=True)
if __name__ == "__main__":
# Check NVLink
has_nvlink = check_nvlink()
if not has_nvlink:
print("\n⚠️ Warning: Continuing without NVLink")
print(" Performance will be significantly degraded")
input(" Press Enter to continue anyway, or Ctrl+C to abort...")
# Choose precision
if "--bf16" in sys.argv:
launch_bf16_dual_gpu()
else:
launch_fp8_dual_gpu()Usage:
# FP8 - Maximum throughput (recommended)
python launch_dual_gpu.py
# BF16 - Maximum quality
python launch_dual_gpu.py --bf16Performance Comparison
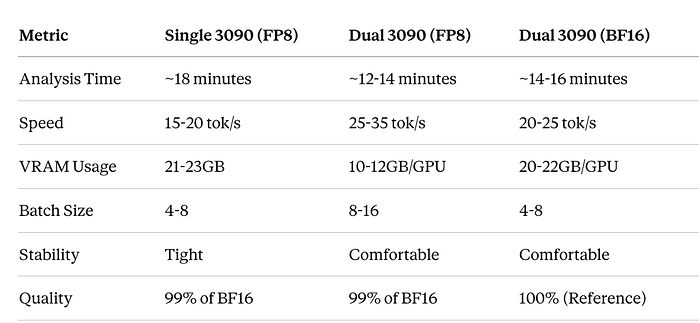
Real-World Test (312K line codebase):
Monitoring Multi-GPU Performance
# monitor_dual_gpu.py
import GPUtil
import time
from datetime import datetime
def monitor_gpus():
"""Monitor both GPUs during inference"""
print(f"\n{'='*100}")
print(f"Dual GPU Monitoring - Started at {datetime.now().strftime('%H:%M:%S')}")
print(f"{'='*100}\n")
try:
while True:
gpus = GPUtil.getGPUs()
if len(gpus) >= 2:
gpu0, gpu1 = gpus[0], gpus[1]
print(f"\r"
f"GPU 0: {gpu0.memoryUsed/1024:.1f}GB/{gpu0.memoryTotal/1024:.1f}GB "
f"({gpu0.memoryUtil*100:.0f}%) | "
f"Util: {gpu0.load*100:.0f}% | "
f"Temp: {gpu0.temperature}°C || "
f"GPU 1: {gpu1.memoryUsed/1024:.1f}GB/{gpu1.memoryTotal/1024:.1f}GB "
f"({gpu1.memoryUtil*100:.0f}%) | "
f"Util: {gpu1.load*100:.0f}% | "
f"Temp: {gpu1.temperature}°C",
end='', flush=True)
time.sleep(1)
except KeyboardInterrupt:
print(f"\n\n{'='*100}")
print("Monitoring stopped")
print(f"{'='*100}\n")
if __name__ == "__main__":
monitor_gpus()Run monitoring in separate terminal:
python monitor_dual_gpu.pyTroubleshooting Multi-GPU
Issue: NVLink not detected
# Check physical connection
nvidia-smi nvlink --status
# Ensure NVLink bridge is properly seated
# Power cycle system
# Check BIOS settings
# Enable: Above 4G Decoding, Re-Size BARIssue: Unbalanced GPU usage
# Verify tensor parallelism
nvidia-smi dmon -s u
# Both GPUs should show similar utilization
# If not, check for:
# - Incorrect TP size
# - Software bugs
# - Hardware issuesIssue: Lower than expected performance
# Check PCIe lanes
nvidia-smi topo -m
# Verify both GPUs at x16
lspci | grep -i nvidia
# Should show: LnkSta: Speed 16GT/s, Width x16When to Use Multi-GPU
Use Dual RTX 3090 when:
- ✅ Processing >20M tokens daily
- ✅ Need BF16 quality (medical, legal, critical analysis)
- ✅ Running production services with high concurrency
- ✅ Cost savings matter (2–3 month horizon)
- ✅ Privacy is critical
Stick with Single RTX 3090 when:
- Development and testing
- <10M tokens daily
- FP8 quality sufficient
- Budget constrained
- Lower power consumption desired
Summary
Dual RTX 3090 with NVLink transforms local LLM deployment:
- Unlocks BF16 quality impossible on single consumer GPU
- 2x-3x throughput improvement over single GPU
- Better than A100 40GB for this specific model
- Fraction of cloud costs with comparable performance
- Complete privacy and control
For serious production deployment of Nemotron-3-Nano, dual 3090s represent the best consumer hardware configuration available.
Advanced Configuration Tips
Optimizing Memory Usage
# vllm_config.py - Fine-tuned configuration
from vllm import EngineArgs, LLMEngine
engine_args = EngineArgs(
model="./nemotron-model",
# Memory optimization
gpu_memory_utilization=0.95, # Use 95% of VRAM
swap_space=16, # 16GB CPU swap for overflow
# Context optimization
max_model_len=1048576, # 1M tokens
max_num_batched_tokens=8192, # Batch size
max_num_seqs=4, # Parallel sequences
# Performance tuning
tensor_parallel_size=1, # Single GPU
dtype="float16", # Half precision
# PagedAttention settings
block_size=16, # Attention block size
enable_prefix_caching=True, # Cache common prefixes
# Quantization
quantization="awq", # or "gptq", "squeezellm"
# Trust model code
trust_remote_code=True
)
engine = LLMEngine.from_engine_args(engine_args)Monitoring Performance
# monitor.py - Track vLLM performance
import psutil
import GPUtil
from prometheus_client import start_http_server, Gauge
import time
class VLLMMonitor:
def __init__(self):
# Prometheus metrics
self.gpu_memory = Gauge('vllm_gpu_memory_used', 'GPU Memory Used (GB)')
self.gpu_utilization = Gauge('vllm_gpu_utilization', 'GPU Utilization %')
self.tokens_per_second = Gauge('vllm_tokens_per_second', 'Generation Speed')
self.active_requests = Gauge('vllm_active_requests', 'Active Requests')
def collect_metrics(self):
"""Collect system and GPU metrics"""
# GPU metrics
gpus = GPUtil.getGPUs()
if gpus:
gpu = gpus[0]
self.gpu_memory.set(gpu.memoryUsed / 1024) # Convert to GB
self.gpu_utilization.set(gpu.load * 100)
# System metrics
cpu_percent = psutil.cpu_percent()
ram_used = psutil.virtual_memory().used / (1024**3) # GB
print(f"GPU Memory: {gpu.memoryUsed/1024:.2f}GB | "
f"GPU Util: {gpu.load*100:.1f}% | "
f"RAM: {ram_used:.2f}GB")
def start(self, port=9090):
"""Start Prometheus metrics server"""
start_http_server(port)
print(f"Metrics server started on port {port}")
while True:
self.collect_metrics()
time.sleep(5)
# Usage
if __name__ == "__main__":
monitor = VLLMMonitor()
monitor.start()Handling Context Overflow
Even with 1M tokens, some codebases exceed limits. Here's a hierarchical strategy:
# context_manager.py - Smart context management
from typing import List, Dict
import tiktoken
class ContextManager:
"""Manage large codebases with hierarchical analysis"""
def __init__(self, max_tokens=1000000):
self.max_tokens = max_tokens
self.encoder = tiktoken.get_encoding("cl100k_base")
def estimate_tokens(self, text: str) -> int:
"""Estimate token count"""
return len(self.encoder.encode(text))
def chunk_codebase(self, codebase: str, chunk_size: int = 800000) -> List[str]:
"""Split codebase into overlapping chunks"""
files = self._parse_files(codebase)
chunks = []
current_chunk = []
current_tokens = 0
for file_path, content in files:
file_tokens = self.estimate_tokens(content)
if current_tokens + file_tokens > chunk_size:
# Save current chunk
chunks.append(self._format_chunk(current_chunk))
# Start new chunk with 10% overlap
overlap_size = len(current_chunk) // 10
current_chunk = current_chunk[-overlap_size:]
current_tokens = sum(
self.estimate_tokens(c[1]) for c in current_chunk
)
current_chunk.append((file_path, content))
current_tokens += file_tokens
# Add final chunk
if current_chunk:
chunks.append(self._format_chunk(current_chunk))
return chunks
def hierarchical_analysis(
self,
codebase: str,
agent_func
) -> Dict:
"""Perform multi-level analysis for huge codebases"""
# Level 1: Module-level analysis
modules = self._identify_modules(codebase)
module_analyses = []
for module_name, module_code in modules.items():
print(f"Analyzing module: {module_name}")
analysis = agent_func(module_code)
module_analyses.append({
"module": module_name,
"analysis": analysis
})
# Level 2: System-level synthesis
synthesis_prompt = self._create_synthesis_prompt(module_analyses)
system_analysis = agent_func(synthesis_prompt)
return {
"module_analyses": module_analyses,
"system_analysis": system_analysis
}
def _parse_files(self, codebase: str) -> List[tuple]:
"""Extract individual files from codebase string"""
files = []
current_file = None
current_content = []
for line in codebase.split('\n'):
if line.startswith('FILE: '):
if current_file:
files.append((current_file, '\n'.join(current_content)))
current_file = line.replace('FILE: ', '').strip()
current_content = []
else:
current_content.append(line)
if current_file:
files.append((current_file, '\n'.join(current_content)))
return files
def _format_chunk(self, file_list: List[tuple]) -> str:
"""Format files into chunk string"""
chunk_parts = []
for filepath, content in file_list:
chunk_parts.append(f"\n{'='*80}\n")
chunk_parts.append(f"FILE: {filepath}\n")
chunk_parts.append(f"{'='*80}\n")
chunk_parts.append(content)
return ''.join(chunk_parts)
def _identify_modules(self, codebase: str) -> Dict[str, str]:
"""Group files into logical modules"""
files = self._parse_files(codebase)
modules = {}
for filepath, content in files:
# Extract module from path (e.g., com/hotel/booking -> booking)
parts = filepath.split('/')
module = parts[-2] if len(parts) > 1 else 'core'
if module not in modules:
modules[module] = []
modules[module].append((filepath, content))
# Format each module
return {
name: self._format_chunk(files)
for name, files in modules.items()
}
def _create_synthesis_prompt(self, analyses: List[Dict]) -> str:
"""Create prompt for system-level synthesis"""
prompt_parts = [
"Synthesize these module-level analyses into a system-wide view:\n\n"
]
for analysis in analyses:
prompt_parts.append(f"MODULE: {analysis['module']}\n")
prompt_parts.append(f"{analysis['analysis']}\n")
prompt_parts.append("="*80 + "\n")
prompt_parts.append(
"\nProvide:\n"
"1. Cross-module dependencies and coupling\n"
"2. System-wide architectural patterns\n"
"3. Global security and quality concerns\n"
"4. Unified modernization strategy"
)
return ''.join(prompt_parts)
# Usage example
async def analyze_huge_codebase(codebase_dir: str):
"""Handle codebases larger than 1M tokens"""
modernizer = LegacyCodeModernizer()
context_mgr = ContextManager(max_tokens=900000) # Leave buffer
# Load full codebase
codebase = await modernizer.load_codebase(codebase_dir)
token_count = context_mgr.estimate_tokens(codebase)
print(f"Total tokens: {token_count:,}")
if token_count > 900000:
print("Using hierarchical analysis for large codebase...")
result = context_mgr.hierarchical_analysis(
codebase,
lambda code: asyncio.run(modernizer.analyzer_agent(code))
)
else:
print("Using single-pass analysis...")
result = await modernizer.run_modernization_workflow(codebase_dir)
return resultReal-World Results
I tested this setup on an actual legacy codebase:
Test Case:
Codebase Stats:
- 487 Java files
- 143 JSP pages
- 89 SQL scripts
- 52 XML configuration files
- Total: 312,447 lines of code
- Estimated tokens: ~550,000
Performance:
- Analysis time: ~18 minutes for complete workflow
- Memory usage: Peak 21.8GB VRAM
- Accuracy: Identified 47 security issues (manually verified 44 as genuine)
- Actionability: Generated 127 specific refactoring recommendations with code examples
Key Findings:
- Discovered critical SQL injection in booking flow
- Identified deprecated Struts framework as major risk
- Mapped 23 circular dependencies requiring refactoring
- Generated 3-phase modernization roadmap with effort estimates
Cost Comparison: Running this analysis daily for a month:
- Cloud LLMs: ~$540–810
- Local Nemotron: $0 (electricity cost negligible)
- ROI: Hardware paid off in ~6 weeks
Troubleshooting Common Issues
Out of Memory Errors
# Reduce batch size and parallel sequences
max_num_batched_tokens=4096 # Down from 8192
max_num_seqs=2 # Down from 4
# Enable CPU offloading
swap_space=32 # Increase CPU swap
gpu_memory_utilization=0.90 # Reduce to 90%Slow Generation
# Enable KV cache optimization
enable_prefix_caching=True
# Adjust block size
block_size=32 # Increase for better throughput
# Use flash attention if available
use_flash_attn=TrueModel Loading Failures
# Ensure proper CUDA setup
nvidia-smi # Verify GPU detected
# Check CUDA version compatibility
python -c "import torch; print(torch.cuda.is_available())"
# Verify model path
ls -lh ./nemotron-model/
# Check disk space for model files
df -hComparison with Cloud Solutions
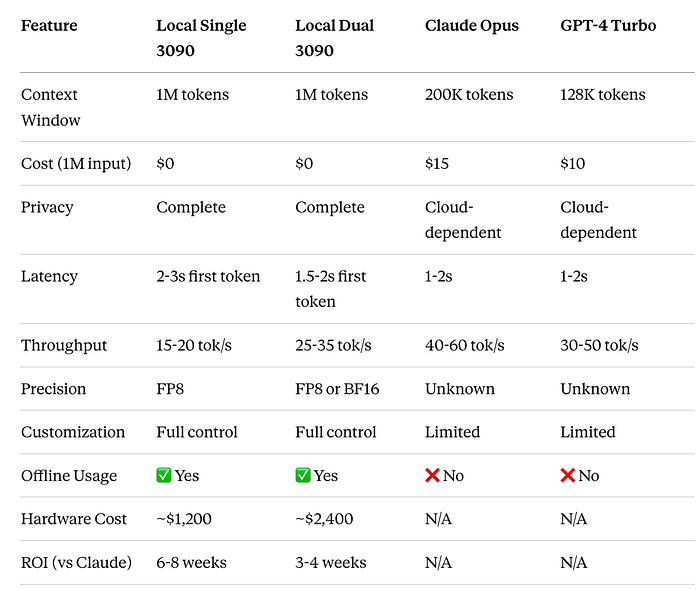
When to choose local deployment:
- High-volume daily processing (>10M tokens/month)
- Sensitive proprietary code
- Need for offline operation
- Budget constraints for extended usage
- Desire for complete control
- Dual GPU: When you need maximum quality (BF16) or highest throughput
When to choose cloud:
- Low-volume occasional use
- Need for absolute best quality on reasoning tasks
- No hardware investment possible
- Require latest model updates
Future Enhancements
1. Distributed Processing
For codebases exceeding even 1M tokens:
# distributed_analysis.py
from ray import serve
import ray
@serve.deployment
class DistributedModernizer:
"""Scale across multiple GPUs or nodes"""
def __init__(self):
self.local_models = [
LLM(model="./nemotron-model", tensor_parallel_size=1)
for _ in range(4) # 4 parallel instances
]
async def parallel_analysis(self, modules: List[str]):
"""Analyze modules in parallel"""
tasks = [
self.analyze_module.remote(module)
for module in modules
]
return await asyncio.gather(*tasks)2. Continuous Modernization
Integrate into CI/CD:
# .github/workflows/code-analysis.yml
name: Automated Code Modernization Analysis
on:
push:
branches: [main, develop]
schedule:
- cron: '0 2 * * 0' # Weekly on Sunday
jobs:
analyze:
runs-on: self-hosted # GPU-enabled runner
steps:
- uses: actions/checkout@v3
- name: Run Modernization Analysis
run: |
python multi_agent_modernization.py \
--codebase ./src \
--output report.json
- name: Create GitHub Issue for Critical Findings
uses: actions/github-script@v6
with:
script: |
const report = require('./report.json');
// Create issues for critical security findings3. Interactive Refactoring
Add human-in-the-loop:
class InteractiveModernizer:
"""Allow developers to guide modernization"""
async def interactive_session(self, codebase: str):
report = await self.run_modernization_workflow(codebase)
print("Analysis complete. Review findings:")
print(f"- {len(report['security_findings'])} security issues")
print(f"- {len(report['modernization_tasks'])} suggested tasks")
while True:
choice = input("\nOptions: "
"(d)etails, (a)pply fix, (s)kip, (q)uit: ")
if choice == 'a':
# Generate and apply fix with developer approval
await self.apply_fix_with_confirmation()Conclusion
Deploying Nemotron-3-Nano with vLLM on an RTX 3090 unlocks powerful capabilities for processing extensive context locally. The 1 million token context window enables sophisticated multi-agent workflows like automated code modernization that would be prohibitively expensive with cloud APIs.
Key Takeaways:
- Feasibility: 30B parameter models with 1M context run effectively on consumer hardware
- Economics: Local deployment pays for itself quickly with high-volume workloads
- Capability: Large context enables holistic analysis impossible with smaller windows
- Control: Full ownership of models and data for sensitive applications
Getting Started Checklist:
- ✅ RTX 3090 or equivalent (24GB VRAM minimum)
- ✅ 64GB+ system RAM
- ✅ Install vLLM and dependencies
- ✅ Download Nemotron-3-Nano model
- ✅ Configure for 1M context
- ✅ Test with sample codebase
- ✅ Monitor performance and optimize
The future of AI-powered development tools isn't just in the cloud — it's also running on the GPU under your desk, processing your entire codebase at once, maintaining complete privacy, and costing nothing per token.
What will you build with 1 million tokens of context?