
A Closer Look at Spark's Architecture
Spark was built to tackle massive data challenges, not to be conservative. It targets petabytes across clusters with fault tolerance, delivering in-memory speed and a rich set of knobs to tune. For a while it was seen as the future; today it remains a foundational pillar of the modern data stack and a rite of passage for anyone working at scale.
The Spark Execution Model
Think of Spark as a distributed orchestra where pieces sit in different regions but perform in harmony. The core idea is to treat data as Resilient Distributed Datasets (RDDs): immutable, fault-tolerant blocks that can span thousands of machines while behaving like a single logical unit.
Spark relies on lazy evaluation. When you write df.filter(col("age") > 25).select("name"), Spark does not start immediately. Instead, it builds a Directed Acyclic Graph (DAG) of your intent and defers execution until an action such as collect() or show() is requested.
A past debugging session reminded me that Spark's laziness can yield surprising optimizations. Triggering the action prompts Spark to optimize the whole chain into an efficient plan rather than running step by step.
This lazy approach enables global optimization. Spark can inspect the entire workflow — filters, joins, and aggregations — and reorganize them for efficiency. It might push predicates down to the data source, avoid unnecessary shuffles, or cache intermediate results you will reuse.
When a job runs, it is broken into stages and tasks. Stages are acts in a play, separated by shuffles where data moves between partitions. Tasks are the individual scenes executed by executors on worker nodes. The driver orchestrates this flow and coordinates results while the executors perform work in parallel. A capable cluster manager allocates resources across machines.
The resilience of Spark comes from RDD lineage. If a node fails, Spark can reconstruct lost partitions by replaying the transformations, keeping the overall computation intact.
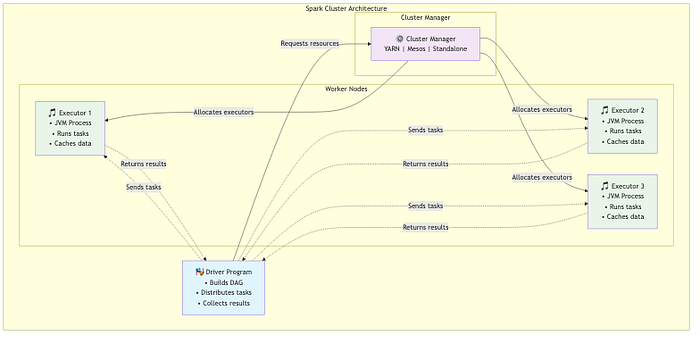
The distributed execution flow demonstrates Spark's elegance: laziness gives way to optimized evaluation once an action is invoked.

And when hiccups occur, RDD lineage makes recovery possible and keeps processing on track.
Catalyst and Tungsten: Spark's Engineered Edge
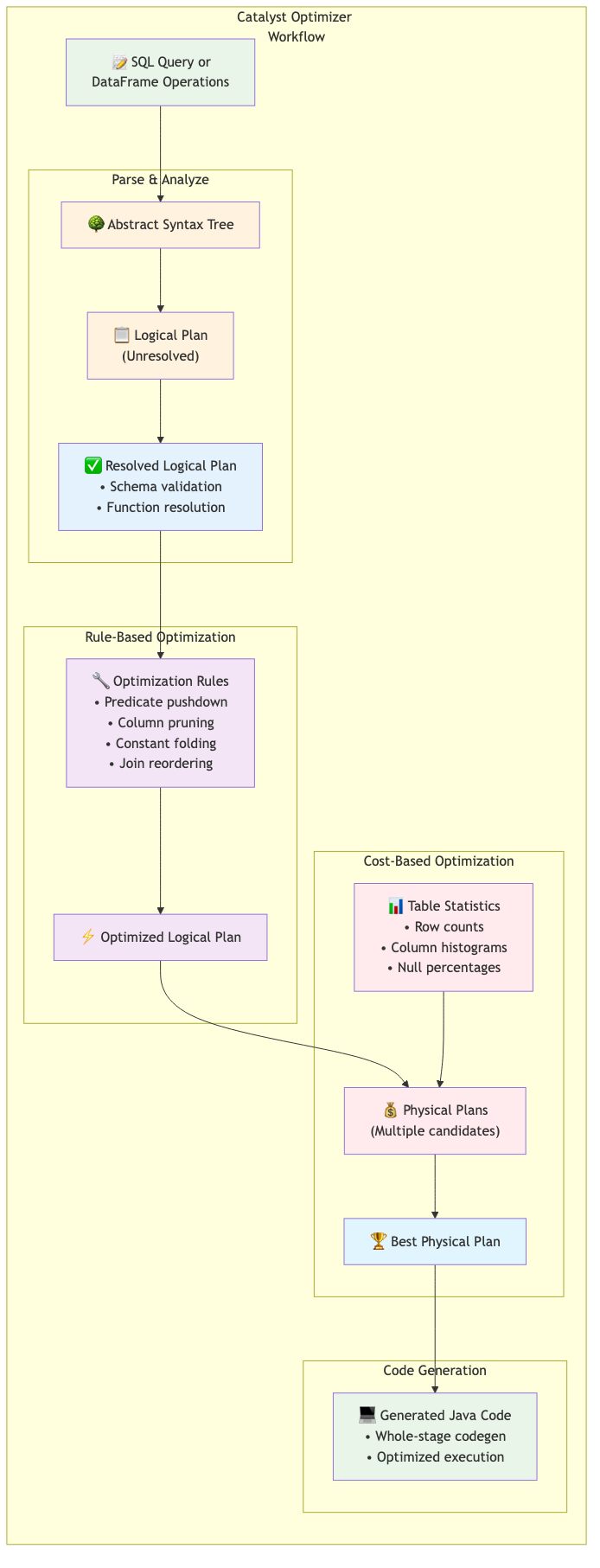
If the execution model is the orchestra, Catalyst and Tungsten are the backstage crew that makes the performance shine. Catalyst is Spark's query optimizer. When you write SQL or DataFrame operations, Catalyst rewrites them into more efficient forms. It parses your query into a logical plan, applies rule-based optimizations such as predicate pushdown and column pruning, and uses cost-based optimization to pick effective physical plans.
I've personally seen Catalyst reshape a complex query, reordering joins and repositioning filters to deliver speedups well beyond manual tuning. The transformation is often invisible to you, yet the results speak for themselves.
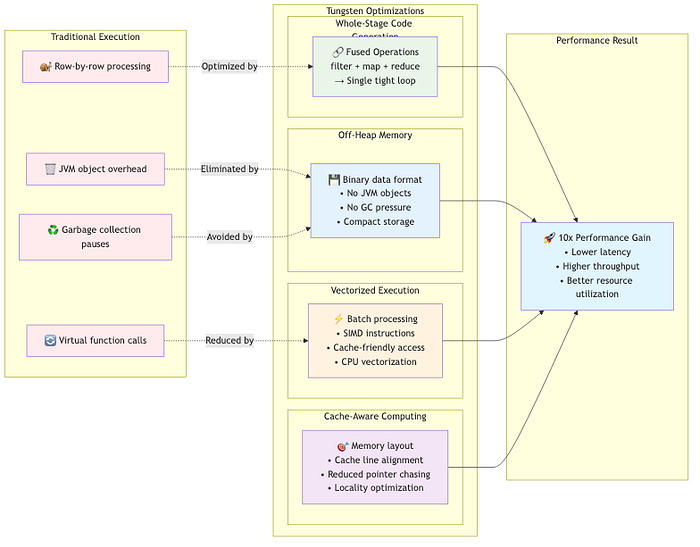
Tungsten targets low-level execution efficiency. It uses whole-stage code generation to fuse multiple operators into tight Java bytecode, reducing function-call overhead. Off-heap memory management minimizes garbage collection pauses, while vectorized execution and cache-conscious data structures extract more performance from modern CPUs.
The magic happens when Catalyst and Tungsten collaborate: you get an optimized logical plan and fast, efficient execution without changing your code. Upgrading Spark versions often brings substantial speedups as these components mature.
Real-World Workflows
Let us speak plainly about Spark's day-to-day usage beyond hype. Batch ETL with Spark SQL shines when handling terabytes of raw logs: ingest data, harmonize schemas, apply business rules, and emit analytics-ready datasets. The unified API lets you read Parquet, join with external sources, apply transformations via SQL or DataFrame APIs, and write results to Delta Lake — within a single framework.
Schema evolution helps accommodate changing data shapes, though defensive design remains prudent. SparkML aimed to bring distributed machine learning to the masses, but today, deep learning workflows are typically better served by dedicated libraries. SparkML remains valuable for large-scale feature engineering and traditional algorithms, at massive scale.
Structured Streaming seeks to unify batch and streaming through a single API. It works well for many use cases but may lag behind purpose-built streaming engines on latency. It suits near-real-time scenarios where simplicity and reliability trump ultra-low latency.
For real-time recommendations processing millions of events per minute, Structured Streaming can work, with careful attention to watermarking, checkpoints, and failure recovery. The sweet spot is often fast-batch use cases rather than true streaming at sub-second latency.
When to Use Spark (and When to Run)
Experience has taught me when Spark earns its keep: with massive datasets, intricate transformations, and time to spare. Its startup overhead makes it less suitable for quick analyses or interactive exploration. For nightly batch workloads spanning petabytes, Spark shines; for sub-second user-facing queries, consider alternatives.
Cluster management and memory planning matter. Spark's in-memory approach is powerful but sensitive to cluster sizing. In some cases, a lighter-weight engine on a single machine can outperform Spark for small datasets.
Consider these options as well: DuckDB for analytical workloads on a single machine, Polars for fast Python analytics with good memory use, Ray or Dask for Python-driven distributed workloads, and Flink for true low-latency streaming.
The key is to match the tool to the problem. Spark is a distributed data processing framework, not a universal solution. Start with simpler tools and graduate to Spark when scale or complexity demands it.
Spark's Legacy in a Post-Spark World
Spark helped democratize big data by making distributed computation accessible via SQL and DataFrame APIs. The era of in‑memory processing, lazy evaluation, and DAG optimization has become a baseline in modern data platforms. The Spark ecosystem — Delta Lake, MLflow, Databricks — has shown how foundational ideas can spawn broader innovation.
Even as newer tools target specific niches more effectively, the Spark design lessons live on: unified analytics, resilient processing, and accessible scalability shape today's data infrastructure. While the future may favor specialized systems — real-time streaming engines, ultra-fast analytical databases, or neural-network-aware ML platforms — Spark's influence remains evident and enduring.